Incrementalist User’s Manual ¶
This manual is for Incrementalist version 0.3.0.
Copyright © 2013 Robert Strandh
Copyright © 2024, 2025 Jan Moringen
Table of Contents
- 1 Introduction
- 2 Concepts
- 3 External Protocols
- 4 Incremental Parsing
- Concept index
- Function and macro and variable and type index
- Changelog
1 Introduction ¶
Incrementalist is a system for incrementally parsing possibly invalid Common Lisp code, which will typically exist within the buffer of a code editor, into concrete and abstract syntax trees. As a first concrete illustration, consider the following simplified example of that process 1:
(let* ((buffer (text.editor-buffer:make-buffer
:initial-contents "(#|foo|# 1 (2 . 3))"))
(analyzer (make-instance 'incrementalist:analyzer :buffer buffer))
(cache (incrementalist:cache analyzer)))
(incrementalist:update analyzer)
(let ((first-result (cdr (first (incrementalist:find-wads-containing-position
cache 0 0)))))
(print-parse-result *standard-output* first-result)))
This code uses Incrementalist to parse (in the incrementalist:update
call) the provided buffer content and present the first entry of the
resulting cache of parse results as a tree which looks similar to the
following:
#<CONS-WAD-WITH-EXTRA-CHILDREN abs:0[0],0 -> 0,19> +-#<BLOCK-COMMENT-WAD rel:0[0],1 -> 0,8> | `-#<WORD-WAD rel:0[0],3 -> 0,6> +-#<ATOM-WAD rel:0[0],9 -> 0,10 raw: 1> `-#<CONS-WAD-WITH-EXTRA-CHILDREN rel:0[0],11 -> 0,18> +-#<ATOM-WAD rel:0[0],12 -> 0,13 raw: 2> +-#<ATOM-WAD rel:0[0],14 -> 0,15 raw: #:|.|> `-#<ATOM-WAD rel:0[0],16 -> 0,17 raw: 3>
Historically, initial aspects of Incrementalist have been developed in the context of the Climacs editor for Common Lisp code. Incrementalist is the result of extracting some of that code into a separate system while enhancing many aspects (in fact, not much of the original ideas or code remains at this point):
- Incrementalist uses the text.editor-buffer library for its buffer representation which has better performance characteristics, especially on large buffers, and makes it easier to write sophisticated parsers for buffer contents compared to the Climacs version.
- In a similar fashion, Incrementalist uses the Eclector library for parsing the contents of Common Lisp buffers instead of the specialized incremental parser used in Climacs. Since Eclector is a conforming but extensible Common Lisp reader, its use reduces maintenance work and ensures that Incrementalist parses the buffer contents in the same way that a Common Lisp compiler would. Eclector also provides access to “skipped material” like comments and handles recovering from syntax errors both of which are essential for a code editor.
- Incrementalist is independent of any particular library for making graphical user interfaces, allowing it to be configured with different such libraries.
2 Concepts ¶
This chapter describes the approaches and abstract data types which Incrementalist uses to incrementally and only when necessary parse buffer contents in order to fill and update a cache of parse results that clients can query. Figure 2.1 presents an overview of the concepts which will be explained in the following sections.
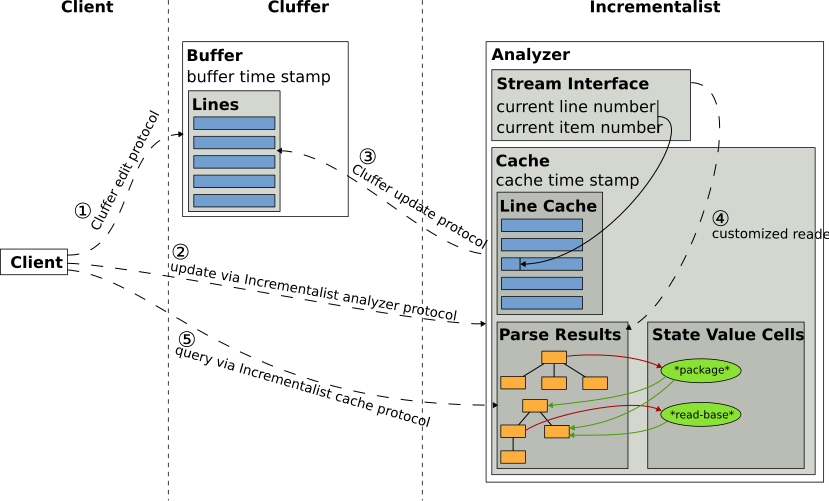
Figure 2.1: Important concepts from the text.editor-buffer and Incrementalist libraries and their relations. Dashed arrows with circled numbers and labels indicate the use of protocols and the typical sequence of events.
As shown in the figure, a client works with a text.editor-buffer buffer and an associated Incrementalist analyzer including the respective sub-structures. The buffer represents some content as sequence of lines each of which is a sequence of items (often characters). In typical usage, the sequence of actions is something like this:
- (1) The client manipulates the buffer content via the text.editor-buffer edit protocol.
- (2) When the client wishes to work with syntax trees that represent the buffer content, the client invokes the Incrementalist analyzer update protocol to bring the analyzer and its cache up-to-date.
- (3) Incrementalist then uses the text.editor-buffer update protocol to determine the buffer lines that have changed since the previous update and invalidates cache data accordingly.
- (4) After that Incrementalist uses Eclector to read (or re-read) in accordance with Common Lisp syntax all buffer regions that have become invalid due to the changes.
- (5) The client can query the up-to-data syntax trees using the Incrementalist cache query protocol.
2.1 Representation of the Editor Buffer ¶
Incrementalist uses the text.editor-buffer library to represent its buffers. We briefly describe the essential aspects of that library below. For detailed information on how it works, see the dedicated documentation.
text.editor-buffer provides two distinct protocols, namely the edit protocol and the update protocol.
- The edit protocol provides operations for editing the buffer contents. It has been designed to be both simple and very efficient. As such, it does not provide operations on larger chunks of contents such as regions. It provides operations only on single items, and operations to split and join lines. These editing operations do not trigger any view updates which is why they can be invoked a large number of times for each user interaction without loss of performance. This feature is taken advantage of in operations on regions and in keyboard macros.
- The update protocol is designed to be run at the frequency of the event loop. It is based on the concept of time stamps. Any number of edit operations can be performed between two invocations of the update protocol, and the update protocol can be invoked at different times for different views, including very rarely for views that are not currently on display. Given that the amount of data displayed in a view is relatively modest, no attempt is made to minimize the modifications to the view. The smallest unit of an update is a line of items.
2.2 Parsing using the Common Lisp Reader ¶
Incrementalist uses a special version of the Common Lisp reader, i.e., Eclector, to parse the contents of a buffer. We use a special version of the reader for the following reasons:
- We need a different action from that of the standard reader when it comes to interpreting tokens. In particular, we do not necessarily want the incremental parser to intern symbols automatically, and we do not want the reader to fail when a symbol with an explicit package prefix does not exist or when the package corresponding to the package prefix does not exists.
- We need for the reader to return not only a resulting expression, but an object that describes the start and end locations in the buffer where the expression was read.
- The reader needs to return source elements that are not returned by an ordinary reader, such as comments and expressions that are skipped by certain other reader macros.
- The reader can not fail but must instead recover in some way when either some invalid syntax is encountered, or when end of file is encountered in the middle of a call.
2.3 Parse Results ¶
We call the data structure for storing parse results which are the (modified) return value of the reader together with start and end location a wad. The following sub-sections describe the structure of a wad and the interpretation of wads as Concrete Syntax Tree nodes respectively. We realize that the nomenclature is slightly confusing since wads are nodes in two different syntax trees which are both concrete syntax trees according to standard terminology. When we capitalize the term as “Concrete Syntax Tree”, we refer to the particular concrete syntax tree representation of the Concrete Syntax Tree library.
2.3.1 WAD Structure ¶
A wad contains the following slots:
- The start and the end location of the wad in the buffer. The start line number within this location information is either absolute which means that it directly corresponds to a line number of the underlying buffer or relative which means that it represents an offset from the start line number of a parent or sibling wad.
- The “raw” expression that was read, with some possible modifications. Some tokens, in particular symbols, are not represented as themselves for reasons mentioned in Parsing using the Common Lisp Reader.
- A list of children. These are wads that were returned by
recursive calls to the reader. The children are represented in the
order they were encountered in the buffer. This order may be different
from the order in which the corresponding expressions appear in the
expression resulting from the call to the reader. Furthermore, the
descendants of a given wad can contain wads which correspond to source
elements that would not be present in the s-expression tree returned by
cl:readat all such as comments or expressions guarded by feature expressions.
The representation of a wad is illustrated in Figure 2.2.
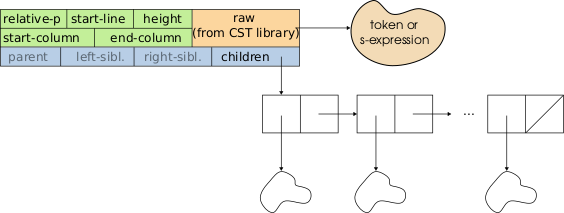
Figure 2.2: Representation of a wad. The major components are highlighted: location information in green, tree structure information in blue and “raw” information in orange. Not all wad classes contain children and “raw” data. The faintly rendered tree structure slots are computed on-demand and are thus always present but not always bound.
A location in the buffer is considered a top-level location if
and only if, when the buffer is parsed by a number of consecutive calls
to cl:read, when this location is reached, the reader is in
its initial state with no recursive pending invocations. Similarly, a
wad is considered a top-level wad if it is the result of an
immediate call to read, as opposed to a recursive call.
Let the initial character of some wad be the first non-whitespace character encountered during the call to the reader that produced this wad. Similarly, let the final character of some wad be the last character encountered during the call to the reader that produced this wad, excluding any look-ahead character that could be un-read before the wad was returned.
The value of the start-line slot for a wad w is computed as
follows:
- If w is absolute, which is the case if and only if w is one of the top-level wads in the prefix (see Prefix and Suffix) or the first top-level wad in the suffix, then the value of this slot is the absolute line number of the initial character of w. The first line of the buffer is numbered 0.
- Otherwise w is relative which is the case for different
kinds of placements of w in the overall hierarchical structure of
wads:
- If w is a top-level wad in the suffix other than the first one,
then the value of this slot is the number of lines between the value of
the slot
start-lineof the preceding wad and the initial character of w. A value of 0 indicates the same line as thestart-lineof the preceding wad. - If w is the first in a list of children of some parent wad
p, then the value of this slot is the number of lines between the
start line of p (which is different from the value of the
start-lineslot of p if p is itself relative) and the initial character of w. - If w is the child other than the first in a list of children of some parent wad, then the value of this slot is the number of lines between the start line of the preceding sibling wad and the initial character of w.
- If w is a top-level wad in the suffix other than the first one,
then the value of this slot is the number of lines between the value of
the slot
The value of the slot height of some wad w is the number of
lines between the start line of w and the final character of
w. If w starts and ends on the same line, then the value of
this slot is 0.
The value of the slot start-column is the absolute column number of
the initial character of this wad. A value of 0 means the
leftmost column.
The value of the slot end-column is the absolute column number of
the final character of the wad.
2.3.2 Concrete Syntax Tree Representation ¶
While the previous section explained the representation of parse results
as wads, the introduction to the Parse Results
section mentioned that some wads are also Concrete Syntax Tree (CST)
nodes. This sub-section focuses on this dual nature. The reason for
having two different views on parse results is that they are used in
different ways: On the one hand, uses such as syntax highlighting are
concerned only with nodes that correspond directly to item sequences in
the buffer, including comments and other “skipped material”. On the
other hand, uses such as semantic analyses of the buffer content as a
Common Lisp program are not concerned with “skipped material” and
instead require an s-expression tree that can be processed using
atom, null, first and rest.
| Aspect | WAD node | CST node |
|---|---|---|
| Purpose | Highlighting and editing | Analysis by early compiler stages |
| Source Location | Always | Optional |
S-expression (cst:raw) | Optional | Always |
| Children | Arbitrary list | Either none or two (first and rest) |
As a concrete example, consider the following Common Lisp code which (assuming the default configuration of the reader) contains a proper list, a dotted list, three numbers and a block comment:
(#|foo|# 1 (2 . 3))
Incrementalist produces the following Concrete Syntax Tree representation for this example:
#<CONS-WAD-WITH-EXTRA-CHILDREN abs:0[0],0 -> 0,19>
+-#<ATOM-WAD rel:0[0],9 -> 0,10 raw: 1>
`-#<CONS-CST raw: ((2 . 3)) {100875D8E3}>
+-#<CONS-WAD-WITH-EXTRA-CHILDREN rel:0[0],11 -> 0,18>
| +-#<ATOM-WAD rel:0[0],12 -> 0,13 raw: 2>
| `-#<ATOM-WAD rel:0[0],16 -> 0,17 raw: 3>
`-#<ATOM-CST raw: NIL {100875D8A3}>
The Concrete Syntax Tree consists of cons nodes and atom nodes. Atom
nodes have no children and cons nodes always have two children one of
which may correspond to the implicit nil that terminates a proper
list but is not present in the source text. “Skipped material” such
as the block comment #|foo|# is not represented. This Concrete
Syntax Tree is suitable for analysis phases such as parsing the
s-expression structure and analyzing the code according to Common Lisp
semantics after that.
In contrast, the interpretation of the example code as a wad tree looks like this:
#<CONS-WAD-WITH-EXTRA-CHILDREN abs:0[0],0 -> 0,19> +-#<BLOCK-COMMENT-WAD rel:0[0],1 -> 0,8> | `-#<WORD-WAD rel:0[0],3 -> 0,6> +-#<ATOM-WAD rel:0[0],9 -> 0,10 raw: 1> `-#<CONS-WAD-WITH-EXTRA-CHILDREN rel:0[0],11 -> 0,18> +-#<ATOM-WAD rel:0[0],12 -> 0,13 raw: 2> +-#<ATOM-WAD rel:0[0],14 -> 0,15 raw: #:|.|> `-#<ATOM-WAD rel:0[0],16 -> 0,17 raw: 3>
The wad tree includes the “skipped material” such as the block comment
and the consing dot that was missing from the Concrete Syntax Tree and
closely reflects the structure of the source code. Note that CST nodes
that are not represented in the source code or otherwise have no source
location such as the implicit nil which terminates the proper list
are not part of the wad tree.
The following figure illustrates both representations at once for the above example:
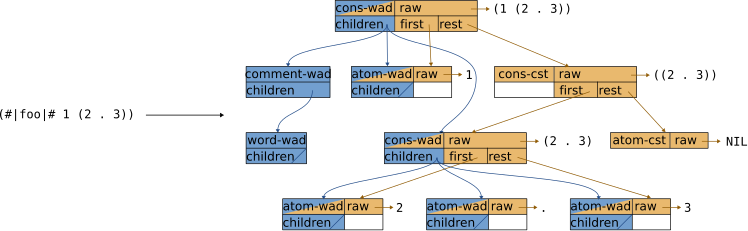
Figure 2.3: Dual representation of wads and CST nodes. WAD aspects are indicated by a blue color, CST aspects are indicated by an orange color.
2.4 Incremental Updates ¶
When Incrementalist produces parse results for a given snapshot (which is identified by a buffer time stamp) of the contents of a buffer in the way described above, Incrementalist stores those results in a cache and updates a time stamp within the cache to the buffer time stamp (see Parse Results for details of the parse result representation). Once the cache is up-to-date, clients can query it, for example to obtain parse results which correspond to a particular range of lines in the buffer.
2.5 The Analyzer ¶
A final concept, the analyzer, ties together the previously mentioned components (See Figure 2.1 for a graphical illustration of all components and their relations):
- The Buffer ¶
The buffer serves as the input for the incremental parsing and contains a time stamp that is incremented for each modification. An analyzer remains attached to a single buffer for the entire lifetime of the analyzer.
- The Reader
Or more precisely, a stream that presents the contents of the buffer to the reader. The analyzer contains (or itself acts as) a Common Lisp stream which can efficiently seek to particular buffer line and item numbers. The modified reader reads changed parts of the buffer contents from this stream.
- The Cache
The analyzer creates and maintains a cache which holds parse results that the reader produces from the buffer stream.
Clients use the Incrementalist library by constructing an analyzer for a given buffer and then repeatedly updating the analyzer and querying the parse results in the associated cache.
3 External Protocols ¶
This chapter describes protocols that clients of Incrementalist can use. As described in the introduction of section Concepts and Figure 2.1, the main activities of clients are on the one hand updating the cache via the analyzer and on the other hand querying and working with parse results, that is wads. Accordingly, the first two sections of this chapter describe protocols for working with wads while the remaining sections focus on updating and querying the cache.
3.1 Package Structure ¶
All symbols that are relevant to external protocols are in the package
named incrementalist. We recommend against client code using
this package in the sense of the :use option to
cl:defpackage or in the sense of calling
cl:use-package. The reason for this recommendation is that we
can not guarantee that future additions to this library will not define
external symbols that conflict with symbols in the common-lisp
package or symbols used by the client for other purposes.
Instead, we recommend that client code use explicit package prefixes, possibly in combination with package-local nicknames. In addition to avoiding future conflicts, this practice will make the origin of the respective symbol obvious from the source code.
3.2 Thread Safety ¶
Operations in Incrementalist are in general not safe to perform concurrently when the operations either directly involve a common object or the involved objects are (directly or indirectly) attached to a common object. An example of the latter case would be concurrent operations on a buffer and the cache associated with the buffer via an analyzer (See Figure 2.1 for the concepts and their relations). Put differently, concurrent operations are safe on unrelated buffer–analyzer–cache triples. When the client obeys certain restrictions, it is possible to operate on a buffer and the associated cache concurrently.
3.3 Token Protocol and Classes ¶
As mentioned in Parsing using the Common Lisp Reader, for some
tokens in the buffer content such as symbols, the corresponding
representation in the raw slot of the containing wad is not simply a
Common Lisp object of the appropriate type but instead an instance of
some token class. These token objects have two purposes:
- In case of symbols, represent symbols without modifying the package system.
- Store information about the “spelling” (use of package prefixes and package markers, radix for numbers) that are not part of the Common Lisp objects that the standard reader produces.
This section describes token classes and readers.
basic-wad +-error-wad `-wad +-cst-wad | +-atom-wad | +-cons-wad | +-labeled-object-wad | | +-labeled-object-definition-wad | | `-labeled-object-reference-wad | `-read-conditional-wad | +-read-negative-conditional-wad | `-read-positive-conditional-wad `-non-cst-wad +-skipped-wad | +-comment-wad | | +-block-comment-wad | | `-semicolon-comment-wad | `-ignored-wad | +-read-suppress-wad | +-reader-macro-wad | `-skipped-conditional-wad | +-skipped-negative-conditional-wad | `-skipped-positive-conditional-wad `-text-wad +-punctuation-wad `-word-wad
- Class: token [incrementalist] ¶
-
Superclass for all token classes.
- Class: symbol-token [incrementalist] ¶
-
Instances of subclasses of this class represent symbol tokens in the buffer content including some information about the concrete “spelling”.
The following readers can be applied to objects of type
incrementalist:symbol-token:
- Generic Function: package-name [incrementalist] symbol-token ¶
-
Return
nilor a string that is the name of the package of the symbol to which symbol-token refers. The valuenilis returned if symbol-token represents an uninterned symbol.Warning: This function will be probably change when Incrementalist transitions to a more complete model of the package system.
- Generic Function: name [incrementalist] symbol-token ¶
-
Return a string that is the name of the symbol to which symbol-token refers.
Warning: This function will be probably change when Incrementalist transitions to a more complete model of the package system.
- Generic Function: package-marker-1 [incrementalist] symbol-token ¶
-
Return
nilor the offset of the first package marker character within the item sequence from which symbol-token has been read.
- Generic Function: package-marker-2 [incrementalist] symbol-token ¶
-
Return
nilor the offset of the second package marker character within the item sequence from which symbol-token has been read.
- Class: uninterned-symbol-token [incrementalist] ¶
-
Instances of this classes represent symbols that do not have a home package.
- Class: interned-symbol-token [incrementalist] ¶
-
Instances of this classes represent symbols that have a home package.
- Class: existing-symbol-token [incrementalist] ¶
-
Instances of this classes represent symbols that exist in the environment.
- Class: non-existing-package-symbol-token [incrementalist] ¶
-
Instances of this classes represent symbols for which the specified package does not exist in the environment.
- Class: non-existing-symbol-token [incrementalist] ¶
-
Instances of this classes represent symbols that do not exist in the environment.
3.4 WAD Protocols and Classes ¶
Incrementalist provides various generic functions for working with wads. Those generic functions are organized into multiple separate protocols for better coherence. Each of the subsections of this section describes one such protocol. The final subsection describes the wad classes to which the protocols can be applied.
3.4.1 Children Protocol ¶
This protocol allows the client to process or obtain the children of a given wad. The children of a wad are also wads.
Note that the sequence of (wad) children considered by the functions in
this section is often different from the (CST) children obtained via the
readers cst:first and cst:rest for several reasons
(see Concrete Syntax Tree Representation):
- CST children may not have an associated source location such as the
second
consin(1 2)while wads always have a source location. - A CST child may be linked to its parent via multiple relations such as
the string
"a"which is thecst:firstandcst:secondof its parent in(#1="a" . #1#). In contrast, a wad child must appear exactly once in the sequence of children of its parent. - Skipped material such as comments does not have a representation as a CST node at all. For the wad tree however, comments and other skipped material appear as children or top-level nodes.
- The hierarchy and order of CST nodes may differ from the source text due to rearrangement by reader macros. In contrast, for the wad tree structure, hierarchy corresponds to containment of text regions and the order of child nodes corresponds to the order of their text regions.
- Generic Function: map-children [incrementalist] function wad ¶
-
Call function with each child of wad as the sole argument.
The calls happen in the order in which the children of wad appear in the source text.
The return value of this function is not specified.
- Generic Function: children [incrementalist] wad ¶
-
Return a fresh list which contains the children of wad.
The order of the elements in the returned list is the order in which the children of wad appear in the source text.
3.4.2 Family Relations Protocol ¶
- Generic Function: parent [incrementalist] wad ¶
-
Return the parent wad of wad or
nilif wad is a top-level wad.
- Generic Function: left-sibling [incrementalist] wad ¶
-
Return the wad that is the left sibling of wad or
nilif wad does not have a left sibling.There are two possible cases in which wad does not have a left sibling:
- If wad is the first child of its parent.
- If wad is a top-level wad and is the first element of the prefix.
- Generic Function: right-sibling [incrementalist] wad ¶
-
Return the wad that is the right sibling of wad or
nilif wad does not have a right sibling.There are two possible cases in which wad does not have a right sibling:
- If wad is the last child of its parent.
- If wad is a top-level wad and is the last element of the suffix.
3.4.3 Basic Wad Protocol ¶
The section describes the basic wad protocol which is applicable to all
wad-like objects including instances of
incrementalist:error-wad and
incrementalist:text-wad.
- Generic Function: absolute-start-line [incrementalist] wad ¶
-
Return a non-negative integer that is the absolute start line number of wad.
warning: An absolute start line number may not be available, for example if wad is a member of the suffix of the cache.
- Generic Function: height [incrementalist] wad ¶
-
Return a non-negative integer that is the difference between the end line number and the start line number of wad.
- Generic Function: end-line [incrementalist] wad ¶
-
Return a non-negative integer that is the absolute end line number of wad.
warning: The absolute end line number is available only if wad is absolute.
- Generic Function: start-column [incrementalist] wad ¶
-
Return a non-negative integer that is the position of the initial character within the start line of wad.
- Generic Function: end-column [incrementalist] wad ¶
-
Return a non-negative integer that is the position of the final character within the end line of wad.
- Generic Function: items [incrementalist] wad ¶
-
Return the sequence of buffer items which belong to wad.
warning: The sequence of buffer items can be obtained only if the absolute start line number of wad is available.
3.4.4 Wad Protocol ¶
The section describes the wad protocol which is applicable to all proper
wad objects but not wad-like objects such as instances of error-wad
and incrementalist:word-wad.
- Generic Function: errors [incrementalist] wad ¶
-
Return a list of errors that are associated with wad.
The elements of the returned list of instances of
incrementalist:error-wad.
- Generic Function: indentation [incrementalist] wad ¶
3.4.5 Wad Classes ¶
The following diagram illustrates the hierarchy of wad classes which Incrementalist provides:
token `-symbol-token +-interned-symbol-token | +-existing-symbol-token | +-non-existing-package-symbol-token | `-non-existing-symbol-token `-uninterned-symbol-token
Instances of subclasses of incrementalist:basic-wad can be
used with the Children Protocol, the Family Relations Protocol and the Basic Wad Protocol. Instances of subclasses of
wad can additionally be used with the Wad Protocol.
- Class: basic-wad [incrementalist] ¶
-
Superclass for wad-like classes. Not intended for use by clients at the moment.
- Class: wad [incrementalist] ¶
-
Superclass for wad classes.
- Class: conditional-wad [incrementalist] ¶
-
Instances of subclasses of this class represent four different kinds of read-time conditional expressions which consist of a “positive” or “negative” feature expression followed by a guarded expression.
The direct subclass
incrementalist:read-conditional-wadis also a subclass ofincrementalist:cst-wad. Instances of its subclasses and represent read-time conditionals that were read (as opposed to skipped) due to the respective feature expression.The direct subclass
incrementalist:skipped-conditional-wadis also a subclass ofincrementalist:skipped-wad. Instances of its subclasses and represent read-time conditionals that were skipped (as opposed to read) due to the respective feature expression.
- Generic Function: feature-expression [incrementalist] sharpsign-wad ¶
-
Return the feature expression of sharpsign-wad.
- Class: cst-wad [incrementalist] ¶
-
Superclass for wad classes that are also subclasses of
concrete-syntax-tree:cst.
- Class: atom-wad [incrementalist] ¶
-
Instances of this class are wads and atom CST nodes at the same time.
The reader
concrete-syntax-tree:rawreturns the raw atom expression.
- Class: cons-wad [incrementalist] ¶
-
Instances of this class are wads and cons CST nodes at the same time.
The reader
concrete-syntax-tree:rawreturns the raw cons expression. The readersconcrete-syntax-tree:firstandconcrete-syntax-tree:restreturn the CST children.Note that the CST children and wad children are usually distinct but not disjoint sets. That is, usually some but not all CST children are also wad children and the other way around (see Concrete Syntax Tree Representation and Children Protocol for details).
- Class: labeled-object-wad [incrementalist] ¶
-
Instances of subclasses of this class represent labeled object definitions and references which are usually written using the
#N=and#N#reader macros.
- Class: labeled-object-definition-wad [incrementalist] ¶
-
Instances of this class represent labeled object definitions which are usually written using the
#N=reader macro.
- Class: labeled-object-reference-wad [incrementalist] ¶
-
Instances of this class represent labeled object references which are usually written using the
#N#reader macro.
- Class: read-conditional-wad [incrementalist] ¶
-
Instances of subclasses of this class represent a read-time conditional expression for which the guarded sub-expression was read (as opposed to skipped). Instances consist of a feature expression and potentially a subsequent expression.
See
incrementalist:skipped-conditional-wadand its subclasses for the representation of the opposite case, that is the guarded expression was skipped.
- Class: read-positive-conditional-wad [incrementalist] ¶
-
Instances of this class represent a read-time condition expression with a
#+feature expression and a guarded expression that was read (as opposed to skipped). In other words, the feature expression must have evaluated to true.
- Class: read-negative-conditional-wad [incrementalist] ¶
-
Instances of this class represent a read-time condition expression with a
#-feature expression and a guarded expression that was read (as opposed to skipped). In other words, the feature expression must have evaluated to false.
- Class: non-cst-wad [incrementalist] ¶
-
Superclass for wad classes that are not sublcasses of
concrete-syntax-tree:cst. Objects that are instances of subclasses of this class mostly represent “skipped material” such as comments and expressions that the reader ignored.
- Class: skipped-wad [incrementalist] ¶
-
Superclass of wad classes that represent “skipped material” such as comments and expressions that the reader ignored.
- Class: ignored-wad [incrementalist] ¶
-
Superclass of wad classes that represent expressions that the reader ignored.
- Class: reader-macro-wad [incrementalist] ¶
-
Instances of this class represent material that was skipped because the reader encountered an unknown or invalid reader macro.
- Class: read-suppress-wad [incrementalist] ¶
-
Instances of this class represent material that was skipped because
cl:*read-suppress*was true.
- Class: skipped-conditional-wad [incrementalist] ¶
-
Instances of subclasses of this class represent a read-time conditional expression for which the guarded sub-expression was skipped (as opposed to read). Instances consist of a feature expression and potentially a subsequent skipped expression.
See
incrementalist:read-conditional-wadand its subclasses for the representation of the opposite case, that is the guarded expression was read.
- Class: skipped-positive-conditional-wad [incrementalist] ¶
-
Instances of this class represent skipped material that consists of a
#+feature expression and potentially a skipped subsequent expression. In other words, the feature expression must have evaluated to false.
- Class: skipped-negative-conditional-wad [incrementalist] ¶
-
Instances of this class represent skipped material that consists of a
#-feature expression and potentially a skipped subsequent expression. In other words, the feature expression must have evaluated to true.
- Class: comment-wad [incrementalist] ¶
-
Instances of subclasses of this class represent comments in the source text.
- Class: block-comment-wad [incrementalist] ¶
-
Instances of this class represent a Common Lisp block comment which has the syntax
#|...|#when the reader operates in its default configuration.
- Class: semicolon-comment-wad [incrementalist] ¶
-
Instances of this class represent a Common Lisp line comment which has the syntax
;...when the reader operates in its default configuration.
- Generic Function: semicolon-count [incrementalist] semicolon-comment-wad ¶
-
This reader returns the number of
#\;characters2 at the beginning of semicolon-comment-wad.
- Class: text-wad [incrementalist] ¶
-
Instances of this class and its subclasses represent text chunks such as words within comments, strings or symbol names.
- Class: punctuation-wad [incrementalist] ¶
-
Instances of this class represent punctuation characters within comments, strings or symbol names.
- Class: word-wad [incrementalist] ¶
-
Instances of this class represent words within comments, strings or symbol names.
- Generic Function: misspelled [incrementalist] word-wad ¶
-
Return true if word-wad contains a spelling error.
- Class: error-wad [incrementalist] ¶
-
Instances of this class encapsulate errors that occurred during the processing of buffer content.
The location information of instances corresponds to that of the encapsulated error conditions.
- Generic Function: condition [incrementalist] error-wad ¶
-
Return the encapsulated condition of error-wad.
The returned object is of type
cl:condition, usually of typecl:errororcl:warning.
3.5 The Associated Buffer Protocol ¶
This tiny protocol consists of a single generic function which looks up
the text.editor-buffer buffer associated with a given object. Clients can
use this protocol for looking up the buffers associated with cache
and incrementalist:analyzer objects.
- Generic Function: buffer [incrementalist] object ¶
-
Return the text.editor-buffer buffer associated with object.
3.6 The Cache Protocol ¶
This protocol extends the
associated buffer protocol,
that is, the incrementalist:buffer is applicable to objects
which implement the cache protocol.
- Generic Function: time-stamp [incrementalist] cache ¶
-
Return
nilor an integer time stamp which indicates the most recent time stamp of the associated buffer for which the cache has been synchronized to the contents of the buffer.
- Generic Function: line-count [incrementalist] cache ¶
-
Return the number of lines in cache.
The returned number reflects the state of the associated buffer at the time returned by the
incrementalist:time-stampreader for cache, not necessarily the current state.
- Generic Function: line-length [incrementalist] cache line-number ¶
-
Return the number of items in the line with number line-number within cache.
The returned number reflects the state of the associated buffer at the time returned by the
incrementalist:time-stampreader for cache, not necessarily the current state.
- Generic Function: line-contents [incrementalist] cache line-number ¶
-
Return the contents of the line with number line-number within cache as a
cl:vectorif items.The returned items reflect the state of the associated buffer at the time returned by the
incrementalist:time-stampreader for cache, not necessarily the current state.
- Generic Function: find-wad-beginning-line [incrementalist] cache line-number ¶
-
Return the wad in cache the initial character of which has the minimal item number within line-number or
nil.
- Generic Function: find-wads-containing-position [incrementalist] cache line-number column-number
&keystart-relation end-relation ¶ -
Return a list of pairs of the form
(n . wad)where wad is a wad, and n is the absolute start line number of wad, such that all the wads are in cache and contain the location defined by line-number and column-number. The list is ordered from the innermost wad containing the location to the top-level wad containing the location. The empty list is returned if the position is not inside any wad.Each of start-relation and end-relation which must be either the symbol
cl:<or the symbolcl:<=select the respective relation for comparisons of locations. start-relation controls how the start location of candidate wads is compared to the location defined by line-number and column-number. end-relation controls the comparison for the end location of candidate wads.
- Generic Function: map-wads-containing-position [incrementalist] function cache line-number column-number
&keystart-relation end-relation ¶ -
Call function once for each wad in cache that contains the location defined by line-number and column-number. The function calls happen in the order from the innermost wad containing the location to the top-level wad containing the location.
Each of start-relation and end-relation which must be either the symbol
cl:<or the symbolcl:<=select the respective relation for comparisons of locations. start-relation controls how the start location of candidate wads is compared to the location defined by line-number and column-number. end-relation controls the comparison for the end location of candidate wads.
3.7 The Analyzer Protocol ¶
This protocol extends the
associated buffer protocol, that
is, the incrementalist:buffer is applicable to objects which
implement the analyzer protocol.
- Generic Function: cache [incrementalist] analyzer ¶
-
Return the cache associated with analyzer.
- Generic Function: update [incrementalist] analyzer ¶
-
Update the cache associated with analyzer according to changes in the buffer associated with analyzer and return information about the processed lines.
This function returns two values: the line number of the first processed line and the line number of the last processed line. These line numbers provide a rough indication of the buffer region and cache items affected by the update. Note that the buffer region indicated by this function may be larger than the region reported by the update protocol of the buffer since a change in one buffer line can cause other buffer lines (an arbitrary number of buffer lines in fact) to be processed.
To retrieve more detailed information produced by this operation, the client queries the updated cache associated with analyzer after the update is complete.
- Class: analyzer [incrementalist] ¶
-
Instances of this class and potential subclasses implement the analyzer protocol by tying together three aspects:
- The analyzer instance consumes the content of an associated text.editor-buffer buffer.
- The analyzer implements the behavior of a Common Lisp stream which enables the Eclector-based reader to read expressions from the analyzer.
- The analyzer maintains the results of reading from the stream in an associated cache of parse results (see Parse Results).
See Figure 2.1 and The Analyzer for an overview of the different components and their relations.
4 Incremental Parsing ¶
As mentioned in Representation of the Editor Buffer, the general control structure for buffer modifications and incremental updates was designed with the following goals:
- Most editing operations should be very fast, even when they involve fairly large chunks of buffer contents. Here, fast means that the response time for interactive editing should be short.
- From a software-engineering point of view, the buffer editing operations should not be aware of the presence of any views.
Notice that it was not a goal that editing operations use as little computational power as possible.
Input events can be divided into two categories:
- Input events that result in some modification to some buffer contents. Inserting and deleting items are in this category. Modifications can be the result of indirect events such as executing a keyboard macro that inserts or deletes items in one or more buffers.
- Input events that have no effect on any buffer contents. Moving a cursor, changing the size of a window, or scrolling a view are typical events in this category. These events influence only the view into a buffer.
When an event in the first category occurs, the following chain of events is triggered:
- The event itself triggers the execution of some command that causes one or more items to be inserted and/or deleted from one or more buffers. Whether this happens as a direct result or as an indirect result of the event makes no difference. The buffers involved are modified, but no other action is taken at this time. Lines that are modified or inserted are marked with the current time stamp and the current time stamp is incremented, possibly more than once.
- At the end of the execution of the command, the syntax update is
executed for all buffers, allowing the contents to be incrementally
parsed according to the syntax associated with the buffer.
warning: There seem to be cases where the syntax of one buffer depends not only on its own associated buffer, but also on the contents of other buffers. It is not a big problem if the dependency is only on the contents of other buffers, but if the dependency is also on the result of the syntax analysis of other buffers, then one syntax update might invalidate another. In that case, it might be necessary to loop until all analyses are complete. This can become very complicated because there can now be circular dependencies so that the entire editor gets caught in an infinite loop.
Finally, visible views are repainted using whatever combination they want of the buffer contents and the result of the syntax update. The syntax update uses the time stamps of lines in the buffer and of the previous syntax update to compute an up-to-date representation of the buffer. This computation is done incrementally as much as possible.
- Each view on display recomputes the data presented to the user and redraws the associated window. Again, time stamps are used to make this computation as incremental as possible.
4.1 Data Structures ¶
4.1.1 Prefix and Suffix ¶
Incrementalist maintains a sequence 3 of top-level wads. This sequence is organized as two ordinary Common Lisp lists, called the prefix and the suffix. Given a top-level location L in the buffer, the prefix contains a list of the top-level wad that precede L and the suffix contains a list of the top-level wads that follow L. The top-level wads in the prefix occur in reverse order compared to order in which they appear in the buffer. The top-level wads in the suffix occur in the same order as they appear in the buffer. the location L is typically immediately before or immediately after the top-level expression in which the cursor of the current view is located, but that is not a requirement. Figure 4.1 illustrates the prefix and the suffix of a buffer with five top-level expressions.

Figure 4.1: Prefix and suffix containing top-level wads.
Either the prefix or the suffix or both may be the empty list. The location L may be moved. It suffices 4 to pop an element off of one of the lists and push it onto the other.
To illustrate the above data structures, we use the following example:
... 34 (f 10) 35 36 (let ((x 1) 37 (y 2)) 38 (g (h x) 39 (i y) 40 (j x y))) 41 42 (f 20) ...
Each line is preceded by the absolute line number. If the wad starting at line 36 is a member of the prefix or if it is the first element of the suffix, it would be represented like this:
36 04 (let ((x 1) (y 2)) (g (h x) (i y) (j x y)))
00 01 ((x 1) (y 2))
00 00 (x 1)
01 00 (y 2)
02 02 (g (h x) (i y) (j x y))
00 00 (h x)
01 00 (i y)
02 00 (j x y)
Since column numbers are uninteresting for our illustration, we show only line numbers. Furthermore, we present a list as a table for a more compact presentation.
4.2 Moving Top-level Wads ¶
Occasionally, some top-level wads need to be moved from the prefix to the suffix or from the suffix to the prefix. There could be several reasons for such moves:
- The place between the prefix and the suffix must always be near the part of the buffer currently on display when the contents are presented to the user. If the part on display changes as a result of scrolling or as a result of the user moving the current cursor, then the prefix and suffix must be adjusted to reflect the new position prior to the presentation.
- After items have been inserted into or deleted from the buffer, the incremental parser may have to adjust the prefix and the suffix so that the altered top-level wads are near the beginning of the suffix.
These adjustments are always accomplished by repeatedly moving a single top-level wad.
To move a single top-level wad P from the prefix to the suffix, the following actions are executed:
- Modify the slot
start-lineof the first wad of the suffix so that, instead of containing the absolute line number, it contains the line number relative to the value of the slotstart-lineof P. - Pop P from the prefix and push it onto the suffix. Rather than
using the straightforward technique, the
conscell referring to P can be reused so as to avoid unnecessary consing.
To move a single top-level wad P from the suffix to the prefix, the following actions are executed:
- If P has a successor S in the suffix, then the slot
start-lineof S is adjusted so that it contains the absolute line number as opposed to the line number relative to the slotstart-lineof P. - Pop P from the suffix and push it onto the prefix. Rather than
using the straightforward technique, the
conscell referring to P can be reused so as to avoid unnecessary consing.
We illustrate this process by showing four possible top-level locations in the example buffer. If all three top-level wads are located in the suffix, we have the following situation:
prefix ... suffix 34 00 (f 10) 02 04 (let ((x 1) (y 2)) (g (h x) (i y) (j x y))) 06 00 (f 20) ...
In the example, we do not show the children of the top-level wad.
If the prefix contains the first top-level expression and the suffix the other two, we have the following situation:
prefix ... 34 00 (f 10) suffix 36 04 (let ((x 1) (y 2)) (g (h x) (i y) (j x y))) 06 00 (f 20) ...
If the prefix contains the first two top-level expressions and the suffix the remaining one, we have the following situation:
prefix ... 34 00 (f 10) 36 04 (let ((x 1) (y 2)) (g (h x) (i y) (j x y))) suffix 42 00 (f 20) ...
Finally, if the prefix contains all three top-level expressions, we have the following situation:
prefix ... 34 00 (f 10) 36 04 (let ((x 1) (y 2)) (g (h x) (i y) (j x y))) 42 00 (f 20) suffix ...
4.3 Incremental Update ¶
Modifications to the buffer are reported at the granularity of entire lines. The following operations are possible:
- A line may be modified.
- A line may be inserted.
- A line may be deleted.
Several different lines may be modified between two incremental updates, and in different ways. The first step in an incremental update step is to invalidate wads that are no longer known to be correct after these modifications. This step modifies the data structure described in Prefix and Suffix in the following way:
- After the invalidation step, the prefix contains the wad preceding the first modified line, so that these wads are still valid.
- The suffix contains those wads following the last modified line. These wads are still valid, but they may no longer be top-level wads, because the nesting may have changed as a result of the modifications preceding the suffix.
- An additional list of residual wads is created. This list contains wads that have not been invalidated by the modifications, i.e. that appear only in lines that have not been modified.
The order of the wads in the list of residual wads is the same as the
order of the wads in the buffer. The slot start-line of each wad in
the list is the absolute line number of the initial character of that
wad.
Suppose, for example, that the buffer contents in our running example was modified so that line 37 was altered in some way, and a line was inserted between the lines 39 and 40. As a result of this update, we need to represent the following wads:
... 34 (f 10) 35 36 (x 1) 37 38 (h x) 39 (i y) 40 41 (j x y) 42 43 (f 20) ...
In other words, we need to obtain the following representation:
prefix ... 34 00 (f 10) residual 36 00 (x 1) 38 00 (h x) 39 00 (i y) 41 00 (j x y) suffix 43 00 (f 20) ...
4.3.1 Processing Modifications ¶
While the list of residual wads is being constructed, its elements are in the reverse order. Only when all buffer updates have been processed is the list of residual wads reversed to obtain the final representation.
All line modifications are reported in increasing order of line number. Before the first modification is processed, the prefix and the suffix are positioned as indicated above, and the list of residual wads is initialized to the empty list.
The following actions are taken, depending on the position of the modified line with respect to the suffix, and on the nature of the modification:
- If a line has been modified, and either the suffix is empty or the modified line precedes the first wad of the suffix, then no action is taken.
- If a line has been deleted, and the suffix is empty, then no action is taken.
- If a line has been deleted, and it precedes the first wad of the suffix,
then the slot
start-lineof the first wad of the suffix is decremented. - If a line has been inserted, and the suffix is empty, then no action is taken.
- If a line has been inserted, and it precedes the first wad of the
suffix, then the slot
start-lineof the first wad of the suffix is incremented. - If a line has been modified and the entire first wad of the suffix is
entirely contained in this line, then remove the first wad from the
suffix and start the entire process again with the same modified line.
To remove the first wad from the suffix, first adjust the slot
start-lineof the second element of the suffix (if any) to reflect the absolute start line. Then pop the first element off the suffix. - If a line has been modified, deleted, or inserted, in a way that may
affect the first wad of the suffix, then this wad is first removed from
the suffix and then processed as indicated below. Finally, start the
entire process again with the same modified line. To remove the first
wad from the suffix, first adjust the slot
start-lineof the second element of the suffix (if any) to reflect the absolute start line. Then pop the first element off the suffix.
Modifications potentially apply to elements of the suffix. When such an element needs to be taken apart, we try to salvage as many as possible of its descendants. We do this by moving the element to a worklist organized as a stack represented as an ordinary Common Lisp list. The top of the stack is taken apart by popping it from the stack and pushing its children. This process goes on until either the top element has no children, or it is no longer affected by a modification to the buffer, in which case it is moved to the list of residual wads.
Let us see how we process the modifications in our running example.
Line 37 has been altered, so our first task is to adjust the prefix and the suffix so that the prefix contains the last wad that is unaffected by the modifications. This adjustment results in the following situation:
prefix ... 34 00 (f 10) residue worklist suffix 36 04 (let ((x 1) (y 2)) (g (h x) (i y) (j x y))) 06 00 (f 20) ...
The first wad of the suffix is affected by the fact that line 37 has
been modified. We must move the children of that wad to the worklist.
In doing so, we make the start-line of the children reflect the
absolute line number, and we also make the start-line of the next
wad of the suffix also reflect the absolute line number. We obtain the
following situation:
prefix ... 34 00 (f 10) residue worklist 36 01 ((x 1) (y 2)) 38 02 (g (h x) (i y) (j x y)) suffix 42 00 (f 20) ...
The first element of the worklist is affected by the modification of
line 37. We therefore remove it from the worklist, and add its children
to the top of the worklist. In doing so, we make the start-line of
those children reflect absolute line numbers. We obtain the following
situation:
prefix ... 34 00 (f 10) residue worklist 36 00 (x 1) 37 00 (y 2) 38 02 (g (h x) (i y) (j x y)) suffix 42 00 (f 20) ...
The first element of the worklist is unaffected by the modification, because it precedes the modified line entirely. We therefore move it to the residue list. We now have the following situation:
prefix ... 34 00 (f 10) residue 36 00 (x 1) worklist 37 00 (y 2) 38 02 (g (h x) (i y) (j x y)) suffix 42 00 (f 20) ...
The first wad of the top of the worklist is affected by the modification. It has no children, so we pop it off the worklist.
prefix ... 34 00 (f 10) residue 36 00 (x 1) worklist 38 02 (g (h x) (i y) (j x y)) suffix 42 00 (f 20) ...
The modification of line 37 is now entirely processed. We know this
because the first wad on the worklist occurs beyond the modified line in
the buffer. We therefore start processing the line inserted between the
existing lines 39 and 40. The first item on the worklist is affected by
this insertion. We therefore remove it from the worklist and push its
children instead. In doing so, we make the start-line slot those
children reflect the absolute line number. We obtain the following
result:
prefix ... 34 00 (f 10) residue 36 00 (x 1) worklist 38 00 (h x) 39 00 (i y) 40 00 (j x y) suffix 42 00 (f 20) ...
The first element of the worklist is unaffected by the insertion because it precedes the inserted line entirely. We therefore move it to the residue list. We now have the following situation:
prefix ... 34 00 (f 10) residue 36 00 (x 1) 38 00 (h x) worklist 39 00 (i y) 40 00 (j x y) suffix 42 00 (f 20) ...
Once again, the first element of the worklist is unaffected by the insertion because it precedes the inserted line entirely. We therefore move it to the residue list. We now have the following situation:
prefix ... 34 00 (f 10) residue 36 00 (x 1) 38 00 (h x) 39 00 (i y) worklist 40 00 (j x y) suffix 42 00 (f 20) ...
The first element of the worklist is affected by the insertion, in that it must have its line number incremented. In fact, every element of the worklist and also the first element of the suffix must have their line numbers incremented. Furthermore, this update finishes the processing of the inserted line. We now have the following situation:
prefix ... 34 00 (f 10) residue 36 00 (x 1) 38 00 (h x) 39 00 (i y) worklist 41 00 (j x y) suffix 43 00 (f 20) ...
With no more buffer modifications to process, we terminate the procedure by moving remaining wads from the worklist to the residue list. The final situation is shown here:
prefix ... 34 00 (f 10) residue 36 00 (x 1) 38 00 (h x) 39 00 (i y) 41 00 (j x y) worklist suffix 43 00 (f 20) ...
4.3.2 Recreating the Cache ¶
Once the cache has been processed so that only wads that are known to be valid remain, the new buffer contents must be fully parsed so that its complete structure is reflected in the cache.
Conceptually, we obtain a complete cache by applying read repeatedly
from the beginning of the buffer, until all top-level wad have been
found. But doing it this way essentially for every keystroke would be
too slow. In this section we explain how the partially invalidated
cache is used to make this process sufficiently fast.
Concept index ¶
| Jump to: | A B C E P S T U W |
|---|
| Jump to: | A B C E P S T U W |
|---|
Function and macro and variable and type index ¶
| Jump to: | A B C E F H I L M N P R S T U W |
|---|
| Jump to: | A B C E F H I L M N P R S T U W |
|---|
Changelog ¶
- Release 0.3 (not yet released)
-
- Incrementalist now uses the text.editor-buffer library instead of the Cluffer
library as its implementation of line-oriented buffers. The new library has
slightly improved protocols and much improved performance compared to Cluffer.
The protocol improvements make the new library mostly but not fully compatible
with Cluffer.
Clients of Incrementalist can benefit from improved buffer and line creation functions which text.editor-buffer provides (See Introduction, the first listing for an example of the new function
text.editor-buffer:make-buffer). - The function
incrementalist:updatenow returns the line numbers of the first and last processed lines.
- Incrementalist now uses the text.editor-buffer library instead of the Cluffer
library as its implementation of line-oriented buffers. The new library has
slightly improved protocols and much improved performance compared to Cluffer.
The protocol improvements make the new library mostly but not fully compatible
with Cluffer.
- Release 0.2 (2026-02-06)
-
- The biggest change is that Incrementalist now tracks dependencies between WADs
that arise due to changes of the reader state.
For example, a
`WAD causes,WADs to be valid in the following sub-expression. However, when the`WAD is changed to, say,'the,WADs have to be re-read with the changed reader state to "witness" that they are no longer valid. A similar situation arises for sub-expressions which follow the consing dot.A different kind of dependency that is less localized arises from non-lexical changes to the reader state such as changing the current package via
in-packageor changing the read base via#.(setf *read-base* 16). These dependencies are now also tracked by Incrementalist although the mechanism for detecting them in expressions that are evaluated at read-time is just a proof-of-concept for now. - Initial unit tests have been added and subsequently extended to cover many specific cases and regressions. One test reads the whole source code of Incrementalist in an incremental way and ensures that various invariants hold at all times.
- Many parts of the system have been optimized:
The code surrounding the
buffer-streamclass has been rewritten to be more efficient.Construction and linking of WADs has been optimized.
- The class hierarchies rooted at
tokenandwadhave been revised multiple times to better represent the kinds and properties of the relevant concrete syntax objects. Examples are tokens for numbers and symbols as well as WADs for labeled objects and read-time conditional expressions.One particular addition are
word-wadandpunctuation-wadwhich are used to represent the components of the strings in symbol names and comments in detail. - Under certain conditions,
word-wadinstances are marked as being spelled correctly or incorrectly using the spell library. As a consequence, Incrementalist now depends on spell. - The concept of some WADs having a dual nature in the sense of conforming to the WAD protocol as well as the CST protocol has been introduced. This concept will be important when WADs will be passed to the s-expression-syntax library in order to be parsed as s-expressions.
- Assertions which check fundamental invariants of Incrementalist’s data-structures as well as debugging tools are now available in separate files which can be loaded when needed.
- Some of the functions which query the cache based on a given buffer location now accept additional arguments which control whether the bounds of WADs should match the given location inclusively or exclusively.
- The manual has been extensively but not yet fully rewritten and extended.
- The biggest change is that Incrementalist now tracks dependencies between WADs
that arise due to changes of the reader state.
- Release 0.1 (not released)
-
- Initial version extracted from Second Climacs repository with core architecture: analyzer, cache, WADs and parsing via Eclector. This version includes a Texinfo-based manual which has been extracted and converted from the LaTeX-based manual of Second Climacs.