Eclector User’s Manual ¶
This manual is for Eclector version 0.12.0.
Copyright © 2010 - 2018 Robert Strandh
Copyright © 2018 - 2025 Jan Moringen
Table of Contents
- 1 Introduction
- 2 External protocols
- 3 Recovering from errors
- 4 Side effects
- 5 Interpretation of unclear parts of the specification
- Concept index
- Function and macro and variable and type index
- Changelog
1 Introduction ¶
Eclector is a portable, implementation-independent version of the
Common Lisp function cl:read, a corresponding readtable and
a quasiquotation facility. As opposed to existing
implementation-specific versions of cl:read, Eclector uses
generic functions to allow clients to customize the exact behavior, such
as the interpretation of tokens.
Another unusual feature of Eclector is its ability to, at the discretion of the client, recover from many syntax errors, continue reading and return a result that somewhat resembles what would have been returned in case the syntax had been valid.
Furthermore, Eclector can be used as a source tracking reader, which is accomplished through a mode of operation that produces parse results which wrap the Common Lisp expressions in objects that can also contain information about the positions in the source code of those expressions. One example of such parse results are concrete syntax trees 1.
2 External protocols ¶
2.1 Packages ¶
2.1.1 Package for basic features ¶
The package for basic features such as customizable source location
construction is named eclector.base. Although this package does
not shadow any symbol in the common-lisp package, we still
recommend the use of explicit package prefixes to refer to symbols in
this package.
2.1.2 Package for ordinary reader features ¶
The package for ordinary reader features is named eclector.reader.
To use features of this package, we recommend the use of explicit
package prefixes, simply because this package shadows and exports names
that are also exported from the common-lisp package. Importing
this package will likely cause conflicts with the common-lisp
package otherwise.
2.1.3 Package for readtable features ¶
The package for readtable-related features is named eclector.readtable.
To use features of this package, we recommend the use of explicit
package prefixes, simply because this package shadows and exports names
that are also exported from the common-lisp package. Importing
this package will likely cause conflicts with the common-lisp
package otherwise.
2.1.4 Package for parse result construction features ¶
The package for features related to the creation of client-defined parse
results is named eclector.parse-result. To use features of this package, we
recommend the use of explicit package prefixes, simply because this
package shadows and exports names that are also exported from the
common-lisp package. Importing this package will likely cause
conflicts with the common-lisp package otherwise.
2.1.5 Package for CST features ¶
The package for features related to the creation of concrete syntax
trees is named eclector.concrete-syntax-tree. To use features of this package, we
recommend the use of explicit package prefixes, simply because this
package shadows and exports names that are also exported from the
common-lisp package. Importing this package will likely cause
conflicts with the common-lisp package otherwise.
2.2 Basic features ¶
In this section, symbols written without package marker are in the
eclector.base package (see Package for basic features).
This package provides the mechanism that enables clients to customize the behavior of the reader. Furthermore this package provides a protocol for customizing a particular aspect of the behavior, namely the construction of source positions and source ranges. Eclector uses source positions and source ranges in signaled conditions and parse results (see Parse result construction features).
- Class: stream-position-condition [eclector.base] ¶
-
This condition type is the supertype of all conditions which are signaled by Eclector functions. An instance of this condition type stores an approximate position in an input stream and an offset from that position. The condition is associated with the stream content at the designated position and offset. The position uses a representation which is controlled by the respective client by adding a method on the
source-positiongeneric function. The offset indicates a distance in characters which must be added to the approximate position to produce the exact position.
- Generic Function: stream-position [eclector.base] condition ¶
-
This generic function can be called by clients in order to obtain the approximate position in the input stream to which condition pertains. The type and interpretation of the returned object depend on the client, namely the presence of client-specific methods on the
source-positiongeneric function. The information returned by the functionsposition-offsetandrange-lengthcan be used to refine the approximate position and compute a range in the input stream respectively.Applicable methods exist for all conditions of type
stream-position-condition.
- Generic Function: position-offset [eclector.base] condition ¶
-
This generic function is called in order to compute the exact position (or start of a range) in the input stream to which condition pertains by refining the approximate position obtained by calling
stream-position. The returned value is an integer (possibly negative) which indicates the offset in characters from the approximate position to the exact position. Since the representation of the approximate position is chosen by the client, applying the offset to that position in a suitable way is also the responsibility of the client. Assuming the object returned by(stream-position condition)is suitable for arithmetic, the exact position is stream-position + position-offset.Applicable methods exist for all conditions of type
stream-position-condition.
- Generic Function: range-length [eclector.base] condition ¶
-
This generic function is called in order to compute the length of the range in the input stream to which condition pertains. The returned value is a non-negative integer which indicates the length of the range in characters. Therefore, assuming the object returned by
(stream-position condition)is suitable for arithmetic, the range covers input the positions [start, start + range-length] where start = stream-position + position-offset.Applicable methods exist for all conditions of type
stream-position-condition.
- Variable: *client* [eclector.base] ¶
-
This variable is used by several generic functions which are called by
eclector.reader:read. The default value of the variable isnil. Clients that want to override or extend the default behavior of some generic function of Eclector should bind this variable to some standard object and provide a method on that generic function, specialized to the class of that standard object.
- Generic Function: source-position [eclector.base] client stream ¶
-
This generic function is called in order to determine the current position in stream. Eclector does not inspect or manipulate the objects returned by this generic function beyond storing them in signaled conditions and passing them as arguments to the
make-source-rangegeneric function. A client is therefore free to define methods on this generic function that return arbitrary objects.The default method on this generic function calls
cl:file-position.
- Generic Function: make-source-range [eclector.base] client start end ¶
-
This generic function is called in order to turn the source positions start and end into a range representation suitable for client. The returned representation designates the range of input characters from and including the character at position start to but not including the character at position end. The default method returns
(cons start end).
2.3 Ordinary reader features ¶
In this section, symbols written without package marker are in the
eclector.reader package
(see Package for ordinary reader features)
The features provided in this package fall into two categories:
- The functions
eclector.reader:read,eclector.reader:read-preserving-whitespace,eclector.reader:read-from-stringandeclector.reader:read-delimited-listwhich, together with standard special variables, replicate the interface of the standard Common Lisp reader (except functions related to readtables which Eclector provides separately, see Readtable features). These functions are discussed in the section Common Lisp reader compatible interface. - The second category is comprised of the
eclector.base:*client*special variable and a collection of protocols which allow customizing the behavior of the reader by defining methods specialized to a particular client on the generic functions of the protocols.
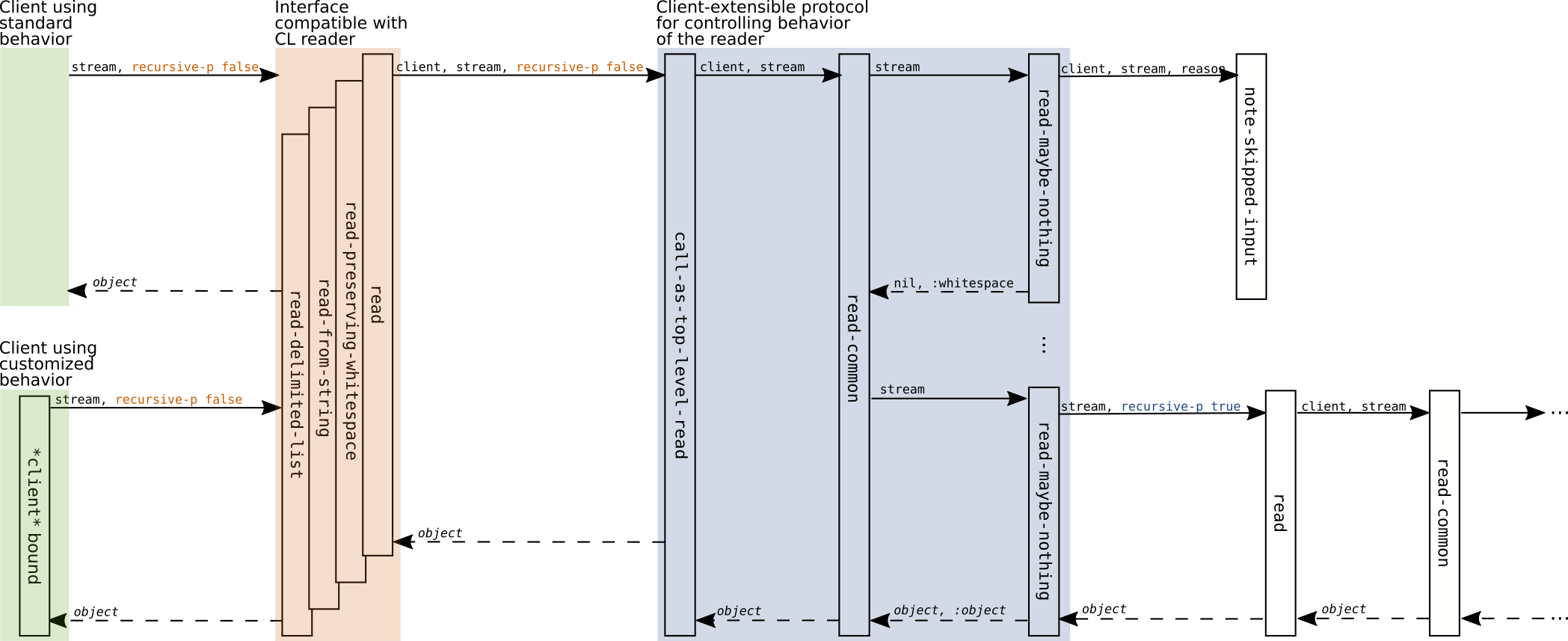
Figure 2.1: Functions and typical function call sequences. Solid arrows represent calls, dashed arrows represent returns from function calls. Labels above arrows represent arguments and return values.
Figure 2.1 illustrates the categorization
into the Common Lisp reader compatible interface and the extensible
behavior protocol as well as typical function call patterns that arise
when the functions eclector.reader:read,
eclector.reader:read-preserving-whitespace,
eclector.reader:read-from-string and
eclector.reader:read-delimited-list are called by client code.
2.3.1 Common Lisp reader compatible interface ¶
The following functions are like their standard Common Lisp
counterparts with the two differences that their names are symbols in
the eclector.reader package and that their behavior can deviate from
that of the standard reader depending on the value of the
eclector.base:*client* variable.
- Function: read [eclector.reader]
&optional(input-stream*standard-input*) (eof-error-pt) (eof-valuenil) (recursive-pnil) ¶ -
This function is the main entry point for the ordinary reader. It is entirely compatible with the standard Common Lisp function
cl:read.
- Function: read-preserving-whitespace [eclector.reader]
&optional(input-stream*standard-input*) (eof-error-pt) (eof-valuenil) (recursive-pnil) ¶ -
This function is entirely compatible with the standard Common Lisp function
read-preserving-whitespace.
- Function: read-from-string [eclector.reader] string
&optional(eof-error-pt) (eof-valuenil)&key(start0) (endnil) (preserve-whitespacenil) ¶ -
This function is entirely compatible with the standard Common Lisp function
cl:read-from-string.
- Function: read-delimited-list [eclector.reader] char
&optional(input-stream*standard-input*) (recursive-pnil) ¶ -
This function is entirely compatible with the standard Common Lisp function
cl:read-delimited-list.
2.3.2 Reader behavior protocol ¶
By defining methods on the generic functions of this protocol, clients can customize the high-level behavior of the reader.

Figure 2.2: Functions and typical function call sequences terminating on the right hand side of the diagram at customizable generic functions which implement aspects of the reader algorithm and standard reader macros. Solid arrows represent calls, dashed arrows represent returns from function calls. Labels above arrows represent arguments and return values.
Figure 2.2 illustrates how the customizable generic functions described in this section are called through the client interface and the implementation of the reader algorithm.
- Generic Function: call-as-top-level-read [eclector.reader] client thunk input-stream eof-error-p eof-value preserve-whitespace-p ¶
-
This generic function is called by
eclector.reader:readifreadis called with a false value for the recursive-p parameter. It calls thunk with the necessary context for a globalreadcall. thunk should read and return an object without consuming any whitespace following the object. If preserve-whitespace-p is false, this function reads up to one character of whitespace after thunk returns. By default, this function returns the object or eof-value returned by thunk as its sole value.Note: This generic function may return more values in addition to the one described above. Clients may use this feature to communicate additional information between methods (see Parse result construction features). Client defined methods on this generic function should accept such additional values when calling thunk, a next method or
eclector.reader:read-commonand themselves return the additional values.The default method on this generic function performs two tasks:
- It establishes a context in which labels (
#N=) and references (#N#) work. - It realizes the requested preserve-whitespace-p behavior.
- It establishes a context in which labels (
- Generic Function: read-common [eclector.reader] client input-stream eof-error-p eof-value ¶
-
This generic function is called by
eclector.reader:read, passing it the value of the variableeclector.base:*client*and the corresponding parameters. By default, this generic function returns the objects as its sole value.Note: This generic function may return more values in addition to the one described above. Clients may use this feature to communicate additional information between methods (see Parse result construction features). Client defined methods on this generic function should accept such additional values when calling a next method or
read-maybe-nothingand themselves return the additional values.Client code can add methods on this function, specializing them to the client class of its choice. The actions that
eclector.reader:readneeds to take for different values of the parameter recursive-p have already been taken beforereadcalls this generic function.
- Generic Function: read-maybe-nothing [eclector.reader] client input-stream eof-error-p eof-value ¶
-
This generic function can be called directly by the client or by the generic function
eclector.reader:read-commonto read an object or consume input without returning an object. If called directly by the client, the call has to be in the dynamic scope of aeclector.reader:call-as-top-level-readcall. The functionread-maybe-nothingeither- encounters the end of input on input-stream and, depending on
eof-error-p either signals an error or returns the values
eof-value and
:eof - or reads one or more whitespace characters an returns the values
niland:whitespace - or reads an object. If
*read-suppress*is true, the function returns nil and:suppress. Otherwise it returns the object and:object. - or consumes a macro character and the characters consumed by the
associated reader macro function if that reader macro function does not
return a value. In this case the function returns
niland:skip.
Note: This generic function may return more values in addition to the ones described above. Clients may use this feature to communicate additional information between methods (see Parse result construction features). Client defined methods on this generic function should accept such additional values when calling a next method and themselves return the additional values.
- encounters the end of input on input-stream and, depending on
eof-error-p either signals an error or returns the values
eof-value and
- Generic Function: note-skipped-input [eclector.reader] client input-stream reason ¶
-
This generic function is called whenever the reader skips some input such as a comment or a form that must be skipped because of a reader conditional. It is called with the value of the variable
eclector.base:*client*, the input stream from which the input is being read and an object indicating the reason for skipping the input. The default method on this generic function does nothing. Client code can supply a method that specializes to the client class of its choice.When this function is called, the stream is positioned immediately after the skipped input. Client code that wants to know both the beginning and the end of the skipped input must remember the stream position before the call to
eclector.reader:readwas made as well as the stream position when the call to this function is made.
- Variable: *skip-reason* [eclector.reader] ¶
-
This variable is used by the reader to determine why a range of input characters has been skipped. To this end, internal functions of the reader as well as reader macros can set this variable to a suitable value before skipping over some input. Then, after the input has been skipped, the generic function
eclector.reader:note-skipped-inputis called with the value of the variable as its reason argument.As an example, the method on
eclector.reader:note-skipped-inputspecialized toeclector.parse-result:parse-result-clientrelays the reason and position information to the client by calling theeclector.parse-result:make-skipped-input-resultgeneric function (see Parse result construction features).
- Generic Function: read-token [eclector.reader] client input-stream eof-error-p eof-value ¶
-
This generic function is called by
eclector.reader:read-commonwhen it has been detected that a token should be read. This function is responsible for accumulating the characters of the token and then callingeclector.reader:interpret-tokenin order to create and return a token.
- Generic Function: interpret-token [eclector.reader] client input-stream token escape-ranges ¶
-
This generic function is called by
eclector.reader:read-tokenin order to create a token from accumulated token characters. The parameter token is a string containing the characters that make up the token. The parameter escape-ranges indicates ranges of characters read from input-stream and preceded by a character with single-escape syntax or delimited by characters with multiple-escape syntax. Values of escape-ranges are lists of elements of the form(start . end)wherestartis the index of the first escaped character andendis the index following the last escaped character. Note thatstartandvarcan be identical indicating no escaped characters. This can happen in cases likea||b. The information conveyed by the escape-ranges parameter is used to convert the characters in token according to the readtable case of the current readtable before a token is constructed.
- Generic Function: check-symbol-token [eclector.reader] client input-stream token escape-ranges position-package-marker-1 position-package-marker-2 ¶
-
This generic function is called by the default method on
eclector.reader:interpret-tokenwhen the syntax of the token corresponds to that of a symbol. This function checks the syntactic validity of the symbol token and signals an error in case of a syntax error. If there are no syntax errors (or error recovery has been performed, see Recovering from errors), this function returns three values:- token or a value derived from token by error recovery operations.
- position-package-marker-1 or a value derived from position-package-marker-1 by error recovery operations.
- position-package-marker-2 or a value derived from position-package-marker-2 by error recovery operations.
The parameter input-stream is the input stream from which the characters were read. The parameter token is a string that contains all the characters of the token. The parameter escape-ranges indicates ranges within token that were preceded by a character with single-escape syntax or delimited by characters with multiple-escape syntax. The parameter position-package-marker-1 contains the index into token of the first package marker, or
nilif the token contains no package markers. The parameter position-package-marker-2 contains the index into token of the second package marker, ornilif the token contains no package markers or only a single package marker.The default method on this generic function checks the positions of the package markers taking into account escape ranges. The method signals errors and allows error recovery as described above.
- Generic Function: interpret-symbol-token [eclector.reader] client input-stream token position-package-marker-1 position-package-marker-2 ¶
-
This generic function is called by the default method on
eclector.reader:interpret-tokenwhen the syntax of the token corresponds to that of a valid symbol. The parameter input-stream is the input stream from which the characters were read. The parameter token is a string that contains all the characters of the token. The parameter position-package-marker-1 contains the index into token of the first package marker, ornilif the token contains no package markers. The parameter position-package-marker-2 contains the index into token of the second package marker, ornilif the token contains no package markers or only a single package marker.The default method on this generic function calls
eclector.reader:interpret-symbolwith a symbol name string and a package indicator.
- Generic Function: interpret-symbol [eclector.reader] client input-stream package-indicator symbol-name internp ¶
-
This generic function is called by the default method on
eclector.reader:interpret-symbol-tokenas well as the default#:reader macro function to resolve a symbol name string and a package indicator to a representation of the designated symbol. The parameter input-stream is the input stream from which package-indicator and symbol-name were read. The parameter package-indicator is a either- a string designating the package of that name
- the keyword
:currentdesignating the current package - the keyword
:keyworddesignating the keyword package nilto indicate that an uninterned symbol should be created
The symbol-name is the name of the desired symbol.
The default method uses
cl:find-package(or*package*when package-indicator is:current) to resolve package-indicator followed bycl:find-symbolorcl:intern, depending on internp, to resolve symbol-name.A second method which is specialized on package-indicator being
nilusescl:make-symbolto create uninterned symbols.
- Generic Function: call-reader-macro [eclector.reader] client input-stream char readtable ¶
-
This generic function is called when the reader has determined that some character is associated with a reader macro. The parameter char has to be used in conjunction with the readtable parameter to obtain the macro function that is associated with the macro character. The parameter input-stream is the input stream from which the reader macro function will read additional input to accomplish its task.
The default method on this generic function simply obtains the reader macro function for char from readtable and calls it, passing input-stream and char as arguments. The default method therefore does the same thing that the standard Common Lisp reader does.
- Generic Function: find-character [eclector.reader] client designator ¶
-
This generic function is called by the default
#\reader macro function to find a character. designator is either- a
stringthat is the name of the character to be found with single and multiple escapes removed, but with the case of all characters as it was in the input. - or a character designating itself.
The function has to either return the character designated by designator or
nilif no such character exists.If designator is a
string, it is the responsibility of the client to disregard the case of characters in designator, for example by producing an uppercase string from designator before looking up the designated character.A default method on this generic function that is not specialized to any particular client but is specialized to designator being a
stringrecognizes the mandatory character names listing in Section 13.1.7 Character Names of the Common Lisp specification. Another default method on this generic function that is not specialized to any particular client but is specialized to designator being acharacterjust returns designator. - a
- Generic Function: make-structure-instance [eclector.reader] client name initargs ¶
-
This generic function is called by the default
#Sreader macro function to construct structure instances. name is a symbol naming the structure type of which an instance should be constructed. initargs is a list the elements of which alternate between string designators naming structure slots and values for those slots.It is the responsibility of the client to coerce the string designators to symbols as if by
(intern (string slot-name) (find-package 'keyword))as described in the Common Lisp specification.There is no default method on this generic function since there is no portable way to construct structure instances given only the name of the structure type.
- Generic Function: evaluate-expression [eclector.reader] client expression ¶
-
This generic function is called by the default
#.reader macro function to perform read-time evaluation. expression is the expression that should be evaluated as it was returned by a recursiveeclector.reader:readcall and potentially influenced by client. The function has to either return the result of evaluating expression or signal an error.The default method on this generic function simply returns the result of
(cl:eval expression).
- Generic Function: check-feature-expression [eclector.reader] client feature-expression ¶
-
This generic function is called by the default
#+and#-reader macro functions to check the well-formedness of feature-expression which has been read from the input stream before evaluating it. For compound expressions, only the outermost expression is checked regarding the atom in operator position and its shape – child expressions are not checked. The function returns an unspecified value if feature-expression is well-formed and signals an error otherwise.The default method on this generic function accepts standard Common Lisp feature expressions, i.e. expressions recursively composed of symbols,
:not-expressions,:and-expressions and:or-expressions.
- Generic Function: evaluate-feature-expression [eclector.reader] client feature-expression ¶
-
This generic function is called by the default
#+and#-reader macro functions to evaluate feature-expression which has been read from the input stream. The function returns either true or false if feature-expression is well-formed and signals an error otherwise.For compound feature expressions, the well-formedness of child expressions is not checked immediately but lazily, just before the child expression in question is evaluated in a subsequent
evaluate-feature-expressioncall. This allows expressions like#+(and my-cl-implementation (special-feature a b)) formto be read without error when the:my-cl-implementationfeature is absent.The default method on this generic function first calls
eclector.reader:check-feature-expressionto check the well-formedness of feature-expression. It then evaluates feature-expression according to standard Common Lisp semantics for feature expressions.
2.3.3 Reader state protocol ¶
The reader state protocol consists of generic functions which the reader and the client call to query and modify the values of reader state aspects. Each aspect is named by a symbol and holds a current value and has a stack of shadowed values like a special variable. Most aspects roughly correspond to a particular reader control variable defined in the Common Lisp specification. In addition to those, Eclector uses aspects for representing the validity of the consing dot as well as the quasiquotation depth and validity in a given context. In total, Eclector defines the following aspects:
cl:*readtable*-
Like the
cl:*readtable*special variable, this aspect controls the readtable object in which the reader looks up the syntax types of characters, the case conversion mode as well as reader macros. By default, values of this aspect must satisfy theeclector.readtable:readtableppredicate. cl:*package*-
Like the
cl:*package*special variable, this aspects controls the package which the reader uses when it looks up or interns symbols in the current package. By default, values of this aspect must be package designators. cl:*read-suppress*-
Like the
cl:*read-suppress*special variable, this aspect controls whether the reader skips over expressions without detailed parsing. cl:*read-eval*-
Like the
cl:*read-eval*special variable, this aspect controls whether the reader evaluates expressions in#.constructs. cl:*features*-
Like the
cl:*features*special variable, this aspect controls the evaluation of features in feature expressions in#+and#-constructs. By default, values of this aspect must be proper lists of symbols. cl:*read-base*-
Like the
cl:*read-base*special variable, this aspect controls the interpretation of tokens by the reader as being integers or ratios. By default, values of this aspect must be of type(integer 1 36). cl:*read-default-float-format*-
Like the
cl:*read-default-float-format*special variable, this aspect controls the floating-point format that the reader uses for floating-point numbers without exponent marker or the default exponent marker. eclector.reader::*quasiquotation-state*-
Warning: Clients should not query, bind or set the value of this aspect at this time.
This aspect controls whether backquote and unquote are allowed in the current context.
eclector.reader::*quasiquotation-depth*-
Warning: Clients should not query, bind or set the value of this aspect at this time.
This aspect tracks the backquote nesting depth in the current context.
eclector.reader::*consing-dot-allowed-p*-
Warning: Clients should not query, bind or set the value of this aspect at this time.
This aspect controls whether the consing dot is allowed in the current context.
- Class: state-value-type-error [eclector.reader] ¶
-
Errors of this type are signaled when an attempt is made to establish an object as the value for a reader state aspect and the supplied object is not of the type required by the aspect.
Since this condition type is a subtype of
cl:type-error, the offending value and the expected type can be retrieved via the readerscl:type-error-datumandcl:type-error-expected-typerespectively. The aspect for which the value was supplied can be retrieved via the readereclector.reader:aspect.
- Generic Function: valid-state-value-p [eclector.reader] client aspect value ¶
-
This generic function is called by the reader to determine whether value is a valid value for the reader state aspect designated by aspect. The generic function returns true if, according to client, value is a valid value for the reader state aspect designated by aspect. aspect must designate a reader state aspect that is recognized by client. At least the aspects listed in the minimal reader state aspects table must be recognized by any client.
With the exceptions of
cl:*readtable*andcl:*package*, the default methods on this generic function recognize state aspects and implement type restrictions informed by the Common Lisp specification:Aspect Type cl:*readtable*(satisfies eclector.readtable:readtablep)cl:*package*(or cl:package cl:symbol cl:string cl:character)(package designator)cl:*read-suppress*t(generalized Boolean)cl:*read-eval*t(generalized Boolean)cl:*features*list(proper list)cl:*read-base*(integer 2 36)(radix)cl:*read-default-float-format*(member short-float single-float double-float long-float)
- Generic Function: state-value [eclector.reader] client aspect ¶
-
Return the current value of the reader state aspect designated by aspect.
aspect must designate a reader state aspect that is recognized by client. At least the aspects listed in the minimal reader state aspects table must be recognized by any client.
The
cl:*package*aspect mandates further explanation: When the client uses only the default methods of the reader state protocol, the return value of this generic function for thecl:*package*aspect is of typecl:packagewhich is a strict subtype of the type of valid values for this aspect. In other words, the defaults coerce package designators to package objects.
- Generic Function: (setf state-value) [eclector.reader] new-value client aspect ¶
-
Set the current value of the reader state aspect designated by aspect to new-value.
aspect must designate a reader state aspect that is recognized by client. At least the aspects listed in the minimal reader state aspects table must be recognized by any client.
new-value is the desired new value for the designated aspect. new-value has to be a valid value for aspect in the sense that
(must return true.eclector.reader:valid-state-value-pclient aspect value)The
cl:*package*aspect mandates further explanation: When the client uses only the default methods of the reader state protocol, the method on this generic function which handles thecl:*package*aspect coerces new-value from designators to package objects so that a subsequenteclector.reader:state-valuecall returns the designated package object.
- Generic Function: call-with-state-value [eclector.reader] client thunk aspect value ¶
-
Call thunk with the reader state aspect designated by aspect bound to value.
aspect must designate a reader state aspect that is recognized by client. At least the aspects listed in the minimal reader state aspects table must be recognized by any client.
The following properties must hold:
- value has to be a valid value for aspect in the sense that
(must return true.eclector.reader:valid-state-value-pclient aspect value) - During the call to thunk and absent any intervening calls to
eclector.reader:call-with-state-value, the expression(must evaluate to value.eclector.reader:state-valueclient aspect)
When Eclector calls this generic function with
cl:*package*as the value of aspect, the value is a always a string designator and never a package object. The default method on this generic function coerces such string designators to package objects so that a subsequenteclector.reader:state-valuecall returns the designated package object. - value has to be a valid value for aspect in the sense that
Backquote and unquote syntax is forbidden in some contexts such as
multi-dimensional array literals (#A) and structure literals
(#S). Eclector tracks and controls whether backquote, unquote or
both should be allowed in a given context using the aspects
eclector.reader::*quasiquotation-state*
and
eclector.reader::*quasiquotation-depth*
mentioned above. Since custom reader macros may also have to control
this state, Eclector provides the following convenience macro:
- Macro: with-quasiquotation-state [eclector.reader] client context quasiquote-forbidden-p unquote-forbidden-p
&bodybody ¶ -
Warning: This macro is experimental and its name is not exported for now.
Control whether backquote syntax, unquote syntax or both are allowed in
readfunctions called during the execution of body. context is a symbol identifying the current context which is used for error reporting. A typical value is the name of the reader macro function in which this macro is used. quasiquote-forbidden-p controls whether backquote syntax should be forbidden. The value:keepcauses the binding to remain unchanged. unquote-forbidden-p controls whether unquote syntax should be forbidden. The value:keepcauses the binding to remain unchanged.
- Macro: with-forbidden-quasiquotation [eclector.reader] context
&optional(quasiquote-forbidden-pt) (unquote-forbidden-pt)&bodybody ¶ -
Warning: This macro is deprecated as of Eclector 0.11 and will be removed in a future version. This macro is replaced by the macro
eclector.reader:with-quasiquotation-statebut that macro is experimental and its name is not exported for now.Disallow backquote syntax, unquote syntax or both in
readfunctions called during the execution of body. context is a symbol identifying the current context which is used for error reporting. A typical value is the name of the reader macro function in which this macro is used. quasiquote-forbidden-p controls whether backquote syntax should be forbidden. The value:keepcauses the binding to remain unchanged. unquote-forbidden-p controls whether unquote syntax should be forbidden. The value:keepcauses the binding to remain unchanged.
2.3.4 Labeled objects and references ¶
Eclector includes implementations of the #= and ## reader
macros and they are present in the default readtable. One way to
customize the behavior of the reader around the #= and ## syntax
is replacing the reader macro functions with custom ones but with this
approach the client code has to reimplement a lot of functionality. As
a finer grained and more composable mechanism for customization,
Eclector provides a protocol for implementing and customizing the
behavior of the #= and ## reader macros, with or without
modifying the readtable. The remainder of this section describes that
protocol.
To start with a bit of terminology, we call the object created by
reading #N=expression a labeled object. We call
N the label of the labeled object and the result of reading
expression the object of the labeled object. We say
that #N=expression defines the labeled object and
#N# references the labeled object. We call the
reference circular if #N# occurs within
expression. Labeled objects are internal to the reader and only
exist during eclector.reader:read calls: before such a call
returns an object, each labeled object within the returned object is
replaced by its respective final object. Callers of
eclector.reader:read and related functions will therefore only
ever see the object, never the labeled object2.
On a technical level, a labeled object is represented as a data type with a current state and a single (possibly unbound) slot containing the object. The following diagrams depicts the possible states of a labeled object together with input patterns and corresponding transitions:

Figure 2.3: Possible states of a labeled object and input patterns which correspond to state transitions.
Put differently, a labeled object can be in the following states:
| State | Object slot |
|---|---|
| undefined | – |
| defined | unbound |
| final | the object |
| referenced (not strictly needed) | the object |
| circular | unbound |
| final (circular) | the object |
| referenced (circular) (not strictly needed) | the object |
The distinction between the states final and referenced on the
one hand and final (circular), and referenced (circular) on the
other hand is not required for implementing labeled objects. Those two
pairs of states are therefore collapsed to just final and final
(circular) in the remainder of this section. The following figure and
paragraphs describe generic functions and methods which implement the
creation, registration, lookup and manipulation of labeled objects
according to the reduced set of states:
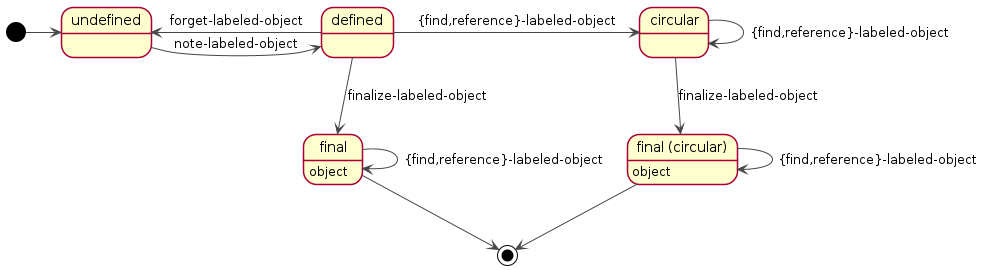
Figure 2.4: Reduced set of states of a labeled object and protocol functions with corresponding state transitions.
In addition to the generic functions referenced in the above diagram,
the generic functions eclector.reader:fixup-graph-p,
eclector.reader:fixup-graph, eclector.reader:fixup
and eclector.reader:new-value-for-fixup are part of the
protocol. Those functions are used to replace labeled objects with
their respective final objects within an object that is about to be
returned to the caller of eclector.reader:read 3. To this end, the
#= reader macro function must inspect and update the state of the
labeled object it is processing after reading expression by
calling eclector.reader:finalize-labeled-object.
eclector.reader:finalize-labeled-object decides whether
eclector.reader:fixup-graph (see below) must be called: If
after reading expression the labeled object is in state
:circular, expression must have contained circular
references and the result of reading it contains labeled objects that
have to be replaced with their respective final objects.
eclector.reader:fixup-graph, eclector.reader:fixup
and eclector.reader:new-value-for-fixup perform this
replacement. The replacement is performed by recursively4 traversing objects which are reachable from the final
object of the labeled objects, for example by visiting the slots of
standard objects, and replacing labeled objects with their respective
final object.
In certain cases, the computational complexity of this traversal and
replacement can be rather high, depending on when and how exactly the
traversal is performed: consider an expression of the form
#1=(1 #1# #2=(2 #2# …)). The nested labeled objects in this
expression are all circular and thus require fixing up. The read
call for the innermost labeled object, say #100=…, returns
first and the fixup processing for the labeled object could be performed
immediately. The problem is that each of the labeled objects would
be processed in the same manner which would lead to a computation
complexity of O(N M) where N is the number of labels and
M is the number of nodes in the object graph rooted at the object
which is returned by the outermost read call. One way to avoid this
problem would be to perform fixup processing only for the outermost
read call. The problem with that approach is that only a small
sub-graph of the whole object graph may be circular in which case most
of the work for traversing the whole graph would be wasted. To address
both problems, Eclector allows clients to track the nesting of labeled
objects and fix up sub-graphs which contain multiple nested objects in
one go (see eclector.reader:fixup-graph-p).
- Generic Function: call-with-label-tracking [eclector.reader] client thunk ¶
-
This generic function is called by the default method on
eclector.reader:call-as-top-level-readin order to establish a context for tracking#=label definitions and##label references around a call to thunk.The default method on this generic function establishes a context in which the default
#=and##reader macro functions can make the appropriate calls toeclector.reader:note-labeled-object,eclector.reader:forget-labeled-object,eclector.reader:find-labeled-object.
- Generic Function: note-labeled-object [eclector.reader] client input-stream label parent ¶
-
This generic function is called by the default
#=reader macro function to note the definition of a labeled object with label label while reading from input-stream. The function creates, registers and returns a representation of the labeled object. The returned object is registered in the sense that a subsequent call toeclector.reader:find-labeled-objectwith arguments client and label returns the same object unlesseclector.reader:forget-labeled-objecthas been called to unregister the object.parent is either
nilor a (previously created) surrounding labeled object. The parent labeled object is provided to allow the client to potentially defer fixup processing for the new labeled object if the processing for the surrounding labeled object subsumes the processing for the new labeled object.Note that, when reading an expression of the form
#N=object, this function is called after reading#N=from input-stream but before readingobject. Consequently, the created and returned labeled object is defined but does not have an object associated with it.The default method on this generic function calls
eclector.reader:make-labeled-objectwith client, input-stream and label to create an object of an unspecified type. The method registers and returns the created object. Client code should manipulate the object only via the generic functions described in this section and in particular not rely on the object being of a particular type (since methods oneclector.reader:make-labeled-objectspecialized to certain client classes could return unexpected objects). The default method requires the context established by the default method oneclector.reader:call-with-label-tracking.
- Generic Function: forget-labeled-object [eclector.reader] client label ¶
-
This generic function is called by the default
#=reader macro function when Eclector reads an invalid labeled object of the form#N=#N#and the caller chooses to recover from the resulting error (see Recovering from errors). In that situation, the remainder of the input is processed as if there had been no labeled object with label N. This function makes the labeled object undefined so that a subsequenteclector.reader:find-labeled-objectcall for label will returnnil.The default method on this generic function requires the context established by the default method on
eclector.reader:call-with-label-tracking.
- Generic Function: find-labeled-object [eclector.reader] client label ¶
-
This generic function is called by the default
##reader macro function to look up the previously registered representation of a labeled object for label. The function returnsnilif no such object has been registered for label and the registered object otherwise.The default method on this generic function requires the context established by the default method on
eclector.reader:call-with-label-tracking.
- Generic Function: make-labeled-object [eclector.reader] client input-stream label parent ¶
-
This generic function is called by
eclector.reader:note-labeled-objectto create and return a representation of a labeled object with label label. parent is eithernilor a previously created, surrounding labeled object which allows the client to potentially defer fixup processing for the new labeled object if the processing for the surrounding labeled object subsumes the processing.The default method on this generic function creates and returns an object of an unspecified type. Client code should manipulate the object only via the generic functions
eclector.reader:labeled-object-state,eclector.reader:finalize-labeled-objectandeclector.reader:reference-labeled-objectand in particular not rely on the object being of a particular type (since methods on this generic function specialized to certain client classes could return unexpected objects).
- Generic Function: labeled-object-state [eclector.reader] client object ¶
-
This generic function is called by the default
#=reader macro function to determine the state of object. This function returnsnilif object is not a labeled object- two values if object is a labeled object: one of the keywords
:defined,:circular,:final,:final/circularand the final object stored in object if the first value is either:finalor:final/circularornilotherwise.
The following table lists all possible return value shapes:
object is a labeled object First value Second value no nilyes :definednilyes :circularnilyes :finalfinal-object yes :final/circularfinal-object Note: This generic function may return more values in addition to the ones described above. Clients may use this feature to communicate additional information between methods (see Parse result construction features). Client defined methods on this generic function should accept such additional values when calling next methods and themselves return the additional values.
The default method on this generic function is applicable to labeled object representations returned by the default methods on
eclector.reader:note-labeled-objectandeclector.reader:make-labeled-object.
- Generic Function: finalize-labeled-object [eclector.reader] client labeled-object object ¶
-
This generic function is called by the default
#=reader macro function after reading a complete labeled object in order to store object in labeled-object and change the state of labeled-object to either:finalor:final/circular. The function returns two values: the finalized labeled-object and the new state of labeled-object.The default method on this generic function is applicable to labeled object representations returned by the default methods on
eclector.reader:note-labeled-objectandeclector.reader:make-labeled-object.
- Generic Function: reference-labeled-object [eclector.reader] client input-stream labeled-object ¶
-
This generic function is called by the default
##reader macro function to process a reference to labeled-object while reading from input-stream. labeled-object must be a representation of a labeled object and has, in the context of the##reader macro function, likely been obtained by callingeclector.reader:find-labeled-object. Depending on the state of labeled-object, this function returns either labeled-object itself or an object that can be returned to the caller as-is. In case labeled-object is returned, it will be replaced by its associated object later, wheneclector.reader:fixup-graphis called.The default method on this generic function is applicable to labeled object representations returned by the default methods on
eclector.reader:note-labeled-objectandeclector.reader:make-labeled-object.
As briefly mentioned above, the generic functions
eclector.reader:fixup-graph and
eclector.reader:fixup traverse and inspect objects in the
object graph reachable from an object that is about to be returned to
the caller of eclector.reader:read. In order to distinguish
ordinary objects from labeled objects that act as placeholders in the
object graph and must be replaced with their respective final objects,
eclector.reader:fixup methods call
eclector.reader:labeled-object-state on all encountered
objects. eclector.reader:labeled-object-state returns nil
for all objects that are not labeled objects and :final for labeled
objects which must be replaced with their final object.
- Generic Function: fixup-graph-p [eclector.reader] client root-labeled-object ¶
-
This generic function is potentially called by a method on
eclector.reader:finalize-labeled-objectto determine whether the object graph reachable from the object of root-labeled-object should be fixed up by callingeclector.reader:fixup-graphwith client and labeled-object.Multiple default methods on this generic function jointly implement the following behavior:
- If root-labeled-object has a parent labeled object, root-labeled-object should not be fixed up immediately (since the fixup processing for ancestor labeled objects will subsume the fixup processing for root-labeled-object).
- If root-labeled-object does not have a parent labeled object but has child labeled objects, root-labeled-object should be fixed up immediately.
- If root-labeled-object does not have a parent labeled object and
is in state
:final/circular, root-labeled-object should be fixed up immediately.
- Generic Function: fixup-graph [eclector.reader] client root-labeled-object
&keyobject-key ¶ -
This generic function is potentially called after the reader has constructed an object graph which is reachable from the object of root-labeled-object and noticed circular references within this graph to fix up circular references before the object of root-labeled-object is returned to the caller (of
eclector.reader:reador related functions).object-key is a function that accepts a labeled object and returns the object of the labeled object.
The default method on this generic function creates a hash table for tracking already processed objects and calls
eclector.reader:fixupwith client, the object of root-labeled-object and the hash table to recursively process objects in the object graph which is reachable from the object of root-labeled-object.
- Generic Function: fixup [eclector.reader] client object traversal-state ¶
-
This generic function is potentially called to apply circularity-related changes to the object constructed by the reader before it is returned to the caller. object is the object that should be modified. traversal-state is an unspecified object that is used, among other things, to track already processed objects (see below). A method specialized to a class, instances of which consist of parts, should modify object by scanning its parts for labeled object markers, replacing found labeled object markers with the respective final object and recursively calling
eclector.reader:fixupfor all parts.To recognize labeled objects which have to be replaced, methods should call
eclector.reader:labeled-object-stateon each part of object and interpret the returned values as follows: ifnilis returned, the part should not be replaced but recursively processed. If:finalis returned as the first value, the part should be replaced with the final object that is returned as the second value. Parts are replaced by mutating object.This generic function is called for side effects – its return value is ignored.
Default methods specializing the object parameter to
cl:cons,cl:array,cl:standard-objectandcl:hash-tableprocess instances of those classes by callingeclector.reader:new-value-for-fixupfor each “place” in object and storing the returned object in the “place”.An unspecialized
:aroundmethod queries and updates traversal-state to ensure that each object reachable from object is processed exactly once. The method also limits the depth of nested function invocations (but importantly not the nesting depth or structure of the processed object graph, in fact the opposite: the limit on function invocation nesting is a consequence of allowing arbitrary object graphs to be processed).Warning: Due to the limit on function call nesting, methods on this generic function must not rely on the traversal from the root object to object resulting in an uninterrupted chain of nested function calls. In particular, bindings of special variables and
cl:unwind-protectcleanups that are established in a call which processes one object may not be in scope in calls which process objects that are logically at a deeper nesting level.
- Generic Function: new-value-for-fixup [eclector.reader] client labeled-object current-value final-value ¶
-
This generic function is called by the generic function
eclector.reader:fixupwhen a new value for a “place” within a circular object must be produced. This function is used when fixup processing is applied to both ordinary objects and parse results.labeled-object is the labeled object marker which will be replaced by the computed value to finalize the circular object.
current-value is the current value of the “place” in the circular object. The value of this parameter is the same as labeled-object when fixup processing is applied to an ordinary object but is different when fixup processing is applied to a parse result. In the latter case, current-value is a parse result and labeled-object is the is ordinary object represented by the parse result.
final-value is the ordinary object that should replace labeled-object in the circular ordinary object regardless of whether fixup processing is performed on ordinary objects or parse results. In the latter case, methods on this generic function must return a suitable parse result that represents final-value and can replace current-value.
The default method on this generic function simply returns final-value.
A method specialized to
(client cst-client)and(current-value cst:cst)returns a CST that represents final-value. Depending on the client, the returned CST is either another occurrence of the CST that represents the definition of final-value or a new CST that explicitly represents the labeled object reference.
2.3.5 S-expression creation ¶
The following generic functions allow clients to construct
representations of quoted and quasiquoted forms as well as
cl:function special forms.
- Generic Function: wrap-in-quote [eclector.reader] client material ¶
-
This generic function is called by the default
'-reader macro function to construct a quotation form in which material is the quoted material.The default method on this generic function returns a result equivalent to
(list 'common-lisp:quote material).
- Generic Function: wrap-in-quasiquote [eclector.reader] client form ¶
-
This generic function is called by the default
`-reader macro function to construct a quasiquotation form in which form is the quasiquoted material.The default method on this generic function returns a result equivalent to
(list 'eclector.reader:quasiquote form).
- Generic Function: wrap-in-unquote [eclector.reader] client form ¶
-
This generic function is called by the default
,-reader macro function to construct an unquote form in which form is the unquoted material.The default method on this generic function returns a result equivalent to
(list 'eclector.reader:unquote form).
- Generic Function: wrap-in-unquote-splicing [eclector.reader] client form ¶
-
This generic function is called by the default
,@-reader macro function to construct a splicing unquote form in which form is the unquoted material.The default method on this generic function returns a result equivalent to
(list 'eclector.reader:unquote-splicing form).
- Generic Function: wrap-in-function [eclector.reader] client name ¶
-
This generic function is called by the default
#'-reader macro function to construct a form that applies thefunctionspecial operator to the name expression.The default method on this generic function returns a result equivalent to
(list 'common-lisp:function form).
2.3.6 Readtable initialization ¶
The standard syntax types and macro character associations used by the ordinary reader can be set up for any readtable object implementing the readtable protocol (see Readtable features). The following functions are provided for this purpose:
- Function: set-standard-syntax-types [eclector.reader] readtable ¶
-
This function sets the standard syntax types in readtable (See Section 2.1.4 Character Syntax Types in the Common Lisp specification).
- Function: set-standard-macro-characters [eclector.reader] readtable ¶
-
This function sets the standard macro characters in readtable (See Section 2.4 Standard Macro Characters in the Common Lisp specification).
- Function: set-standard-dispatch-macro-characters [eclector.reader] readtable ¶
-
This function sets the standard dispatch macro characters, that is sharpsign and its sub-characters, in readtable (See Section 2.4.8 Sharpsign in the Common Lisp specification).
- Function: set-standard-syntax-and-macros [eclector.reader] readtable ¶
-
This function sets the standard syntax types and macro characters in readtable by calling the above three functions.
2.4 Readtable features ¶
In this section, symbols written without package marker are in the
eclector.readtable package (see Package for readtable features).
This package exports two kinds of symbols:
- Symbols the names of which correspond to the names of symbols in the
common-lisppackage. The functions bound to these symbols are generic versions of the corresponding standard Common Lisp functions. Clients can define custom readtables by defining methods on these generic functions. - Symbols bound to additional functions and condition types.
- Generic Function: readtablep [eclector.readtable] object ¶
-
This function is the generic version of the standard Common Lisp function
cl:readtablep. The function returns true if object can be used as a readtable in Eclector via the protocol functions in theeclector.readtablepackage. The default method returnsnil.
TODO
2.5 Parse result construction features ¶
In this section, symbols written without package marker are in the
eclector.parse-result package (see Package for parse result construction features).
This package provides clients with a reader that behaves similarly to
cl:read but returns custom parse result objects controlled by
the client. Some parse results correspond to things like symbols,
numbers and lists that cl:read would return, while others, if
the client chooses, represent comments and other kinds of input that
cl:read would discard. Furthermore, clients can associate
source location information with parse results.
Clients using this package pass a “client” object for which methods on
the generic functions described below are applicable to
eclector.parse-result:read,
eclector.parse-result:read-preserving-whitespace or
eclector.parse-result:read-from-string. Suitable client classes can be
defined by using eclector.parse-result:parse-result-client as a
superclass and at least defining a method on the generic function
eclector.parse-result:make-expression-result.
When a client constructs parse results, some of the generic functions for customizing the behavior of the reader (see Reader behavior protocol, see Labeled objects and references) return additional values:
| Generic function | Situation | Ordinary values | Extended values |
|---|---|---|---|
eclector.reader:call-as-top-level-read | object | object | object, parse result, orphan results |
eclector.reader:read-common | object | object | object, parse result |
eclector.reader:read-maybe-nothing | object | object, kind | object, kind, parse result |
eclector.reader:call-as-top-level-read | end of input | eof-value | eof-value, orphan results |
eclector.reader:read-common | end of input | eof-value | eof-value |
eclector.reader:read-maybe-nothing | end of input | eof-value, :eof | eof-value, :eof |
eclector.reader:labeled-object-state | any | state, final object | state, final object, parse result, inner labeled object |
Note how eclector.reader:call-as-top-level-read and
eclector.reader:read-common return fewer values for the “end
of input” situation. This difference in return value count allows the
caller to recognize the “end of input” situation even if
eof-value is an object that could be read such as nil. Using
such an eof-value makes sense for clients which construct parse
results since top-level eclector.parse-result:read calls return these
parse results so that there is no risk of confusing the chosen
eof-value, even if something like nil, with having read a
similar object.
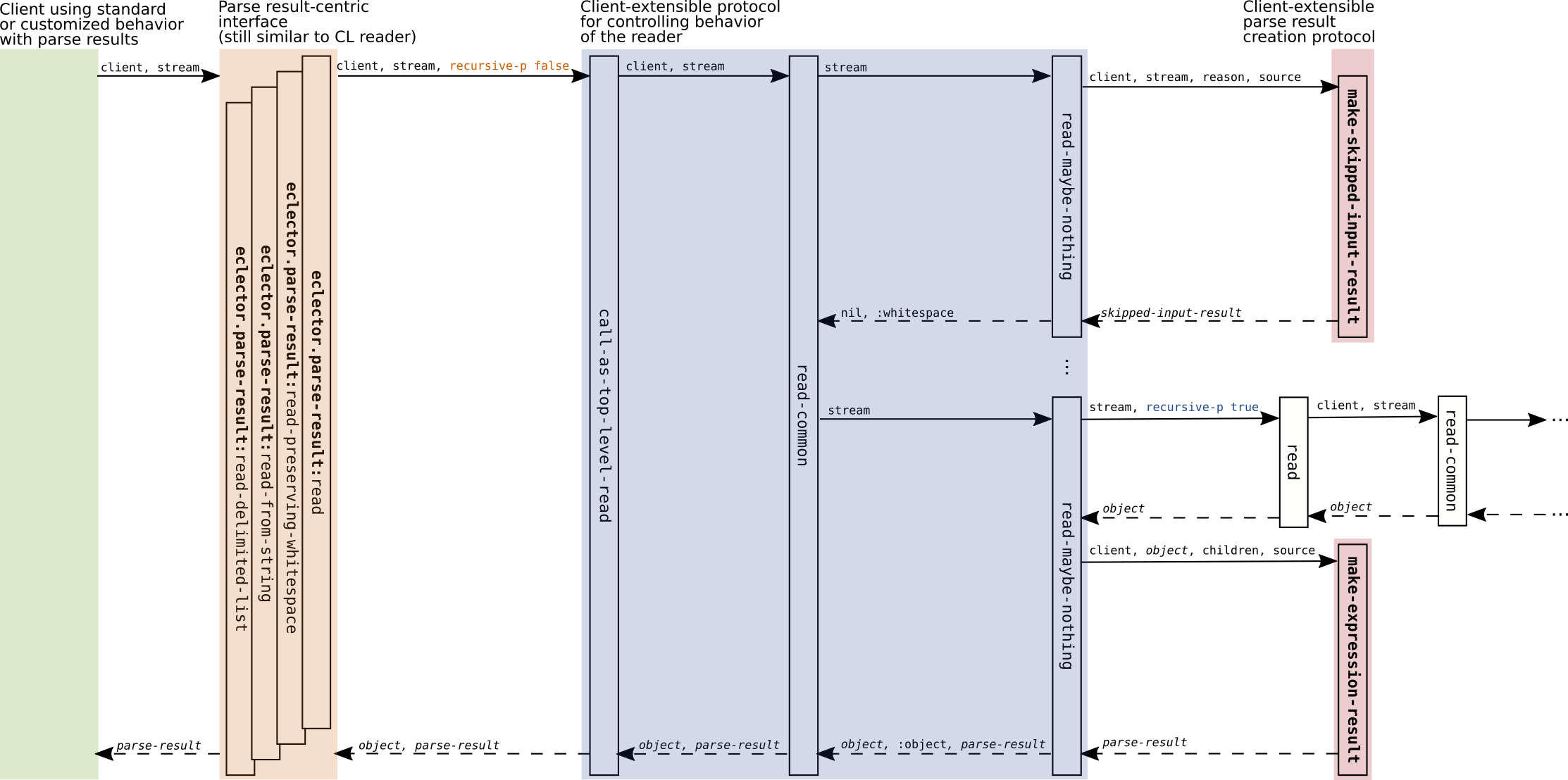
Figure 2.5: Functions and typical function call sequences. Solid arrows represent calls, dashed arrows represent returns from function calls. Labels above arrows represent arguments and return values. Differences from the non-parse result version are highlighted with bold text.
Figure 2.5 shows typical function call
patterns, including ordinary and additional return values, that arise
when the functions eclector.parse-result:read,
eclector.parse-result:read-preserving-whitespace,
eclector.parse-result:read-from-string
are called by client code.
- Function: read [eclector.parse-result] client
&optional(input-stream*standard-input*) (eof-error-pt) (eof-valuenil) ¶ -
This function is the main entry point for this variant of the reader. It is in many ways similar to the standard Common Lisp function
cl:read. The differences are:- A client instance must be supplied as the first argument.
- The first return value, unless eof-value is returned, is an arbitrary parse result object created by the client, not generally the read object.
-
The second return value, unless eof-value is returned, is a list
of “orphan” results. These results are return values of
eclector.parse-result:make-skipped-input-resultand arise when skipping input at the toplevel such as comments which are not lexically contained in lists:#|orphan|# (#|not orphan|#). - The function does not accept a recursive parameter since it sets
up a dynamic environment in which calls to
eclector.reader:readbehave suitably.
- Function: read-preserving-whitespace [eclector.parse-result] client
&optional(input-stream*standard-input*) (eof-error-pt) (eof-valuenil) ¶ -
This function is similar to the standard Common Lisp function
cl:read-preserving-whitespace. The differences are the same as described above foreclector.parse-result:readcompared tocl:read.
- Function: read-from-string [eclector.parse-result] client string
&optional(eof-error-pt) (eof-valuenil)&key(start0) (endnil) (preserve-whitespacenil) ¶ -
This function is similar to the standard Common Lisp function
cl:read-from-string. The differences are:- A client instance must be supplied as the first argument.
- The first return value, unless eof-value is returned, is an arbitrary parse result object created by the client, not generally the read object.
- The third return value, unless eof-value is returned, is a list of “orphan” results (Described above).
- Class: parse-result-client [eclector.parse-result] ¶
-
This class should generally be used as a superclass for client classes using this package.
- Generic Function: make-expression-result [eclector.parse-result] client result children source ¶
-
This generic function is called in order to construct a parse result object. The value of the result parameter is the raw object read. The value of the children parameter is a list of already constructed parse result objects representing objects read by recursive
readcalls. The value of the source parameter is a source range, as returned byeclector.base:make-source-rangeandeclector.base:source-positiondelimiting the range of characters from which result has been read.This generic function does not have a default method since the purpose of the package is the construction of custom parse results. Thus, a client must define a method on this generic function.
- Generic Function: make-skipped-input-result [eclector.parse-result] client stream reason children source ¶
-
This generic function is called after the reader skipped over a range of characters in stream. It returns either
nilif the skipped input should not be represented or a client-specific representation of the skipped input. The value of the children parameter is a list of already constructed parse result objects which represent object read by recursivereadcalls (Such as the feature expression and the ignored expression in#+(and (or) some-feature) skipped-expression). The value of the source parameter designates the skipped range using a source range representation obtained viaeclector.base:make-source-rangeandeclector.base:source-position.Reasons for skipping input include comments, the
#+and#-reader macros and*read-suppress*. The aforementioned reasons are reflected by the value of the reason parameter as follows:Input Value of the reason parameter Comment starting with ;(:line-comment . 1)Comment starting with ;;(:line-comment . 2)Comment starting with n ;(:line-comment . n)Comment delimited by #||#:block-comment#+false-expression(:sharpsign-plus . false-expression)#-true-expression(:sharpsign-minus . true-expression)*read-suppress*is true*read-suppress*A reader macro returns no values :reader-macroThe default method returns
nil, that is the skipped input is not represented as a parse result.
2.6 CST reader features ¶
In this section, symbols written without package marker are in the
eclector.concrete-syntax-tree package (see Package for CST features).
- Function: read [eclector.concrete-syntax-tree]
&optional(input-stream*standard-input*) (eof-error-pt) (eof-valuenil) ¶ -
This function is the main entry point for the CST reader. It is mostly compatible with the standard Common Lisp function
cl:read. The differences are:- The return value, unless eof-value is returned, is an instance of
a subclass of
concrete-syntax-tree:cst. - The function does not accept a recursive parameter since it sets
up a dynamic environment in which calls to
eclector.reader:readbehave suitably.
- The return value, unless eof-value is returned, is an instance of
a subclass of
- Function: read-preserving-whitespace [eclector.concrete-syntax-tree]
&optional(input-stream*standard-input*) (eof-error-pt) (eof-valuenil) ¶ -
This function is similar to the standard Common Lisp function
cl:read-preserving-whitespace. The differences are the same as described above foreclector.concrete-syntax-tree:readcompared tocl:read.
- Function: read-from-string [eclector.concrete-syntax-tree] string
&optional(eof-error-pt) (eof-valuenil)&key(start0) (endnil) (preserve-whitespacenil) ¶ -
This function is similar to the standard Common Lisp function
cl:read-from-string. The differences are the same as described above foreclector.concrete-syntax-tree:readcompared tocl:read.
3 Recovering from errors ¶
3.1 Error recovery features ¶
Eclector offers extensive support for recovering from many syntax
errors, continuing to read from the input stream and return a result
that somewhat resembles what would have been returned in case the syntax
had been valid. To this end, a restart named
eclector.reader:recover is established when recoverable errors are
signaled:
- Restart: recover [eclector.reader] ¶
-
Try to recover from a signaled syntax error by moving the input stream to a position from which the reader can resume reading and returning a replacement value (see Recoverable errors) from the innermost
readcall.
Like the standard Common Lisp restart cl:continue, this
restart can be invoked by a function of the same name:
- Function: recover [eclector.reader]
&optionalcondition ¶ -
This function recovers from an error by invoking the most recently established applicable
eclector.reader:recoverrestart. If no such restart is currently established, it returnsnil. If condition is non-nil, only restarts that are either explicitly associated with condition, or not associated with any condition are considered.
When a read call during which error recovery has been
performed returns, Eclector tries to return an object that is
similar in terms of type, numeric value, sequence length, etc. to what
would have been returned in case the input had been well-formed. For
example, recovering after encountering the invalid digit in
#b11311 returns either the number #b11011 or the
number #b11111.
3.2 Recoverable errors ¶
A syntax error and a corresponding recovery strategy are characterized
by the type of the signaled condition and the report of the established
eclector.reader:recover
restart respectively. Attempting to list and describe all examples of
both would provide little insight. Instead, this section describes
different classes of errors and corresponding recovery strategies in
broad terms:
- Replace a missing numeric macro parameter or ignore an invalid numeric
macro parameter. Examples:
#=1⟶1,#5P"."⟶#P"." - Add a missing closing delimiter. Examples:
"foo⟶"foo",(1 2⟶(1 2),#(1 2⟶#(1 2),#C(1 2⟶#C(1 2) - Replace an invalid digit or an invalid number with a valid one. This
includes digits which are invalid for a given base but also things like
0 denominator. Examples:
#12rc⟶1,1/0⟶1,#C(1 :foo)⟶#C(1 1) - Replace an invalid character with a valid one. Example:
#\foo⟶#\? - Invalid constructs can sometimes be ignored. Examples:
(,1)⟶(1),#S(foo :bar 1 2 3)⟶#S(foo :bar 1) - Excess parts can often be ignored. Examples:
#C(1 2 3)⟶#C(1 2),#2(1 2 3)⟶#2(1 2) - Replace an entire construct by some fallback value. Example:
#S(5)⟶nil,(#1=)⟶(nil)
3.3 Potential problems ¶
Note that attempting to recover from syntax errors may lead to apparent
success in the sense that the read call returns an object, but this
object may not be what the caller wanted. For example, recovering from
the missing closing " in the following example
(defun foo (x y) "My documentation string (+ x y))
results in (DEFUN FOO (X Y) "My documentation string<newline> (+ x y))"),
not (DEFUN FOO (X Y) "My documentation string" (+ x y)).
4 Side effects ¶
This chapter describes potential side effects of calling
eclector.reader:read,
eclector.reader:read-preserving-whitespace or
eclector.reader:read-from-string for different kinds of
clients.
4.1 Potential side effects for the default client ¶
The following destructive modifications are considered uninteresting and ignored in the remainder of this section:
- Changes to the state of streams passed to the functions mentioned above.
- Changes to objects within expressions currently being read.
Furthermore, the remainder of this section is written under the following assumptions:
- The stream object passed to
eclector.reader:readdoes not cause additional side effects on its own. - The variable
eclector.base:*client*is bound to an object for which there are no custom applicable methods on generic functions belonging to protocols provided by Eclector that introduce additional side effects. - The aspect
cl:*readtable*is bound to an object for which- there are no custom applicable methods on generic functions belonging to protocols provided by Eclector that introduce additional side effects
- no non-default macro functions have been installed
If any of the above assumptions does not hold, “all bets are off” in the sense that arbitrary side effects other than the ones described below are possible. For notes regarding non-default clients, See Potential side effects for non-default clients.
4.1.1 Symbols and packages (default client) ¶
The default method on the generic function
eclector.reader:interpret-symbol may create and intern
symbols, thereby modifying the package system.
4.1.2 Read-time evaluation (default client) ¶
The default method on the generic function
eclector.reader:evaluate-expression uses cl:eval to
evaluate arbitrary expressions, potentially causing side effects. With
the default readtable, the generic function is only called by the macro
function of the #. reader macro.
4.1.3 Standard reader macros (default client) ¶
The default method on the generic function
eclector.reader:call-reader-macro can cause side effects by
calling macro functions that cause side effects. The following standard
reader macros potentially cause side-effects:
#.as described in Read-time evaluation (default client).
4.2 Potential side effects for non-default clients ¶
4.2.1 Symbols and packages ¶
In addition to the potential side effects described in Symbols and packages (default client), strings passed as the third argument of
eclector.reader:interpret-token are potentially destructively
modified during conversion to the current readtable case.
4.2.2 Read-time evaluation ¶
The same considerations as in Read-time evaluation (default client) apply.
4.2.3 Structure instance creation ¶
Clients defining methods on
eclector.reader:make-structure-instance which implement the
standard behavior of calling the default constructor (if any) of the
named structure should consider side effects caused by slot initforms of
the structure. The following example illustrates this problem:
(defvar *counter* 0) (defstruct foo (bar (incf *counter*))) #S(foo) *counter* ⇒ 1 #S(foo) *counter* ⇒ 2
4.2.4 Circular structure ¶
The eclector.reader:fixup generic function potentially
modifies its second argument destructively. Clients that define methods
on eclector.reader:make-structure-instance should be aware of
this potential modification in cases like #1=#S(foo :bar #1#).
Similar considerations apply for other ways of constructing compound
objects such as #1=(t . #1#).
4.2.5 Standard reader macros ¶
The following standard reader macros could cause or be affected by side effects when combined with a non-standard client:
#.as described in Read-time evaluation (default client).#Sas described in Structure instance creation.(,#(and#Sas described in Circular structure.- The
,.(i.e. destructively splicing) variant of the,reader macro does not currently destructively modify the surrounding object, but clients should not rely on this fact. This consideration applies to clients that install non-standard macro functions for the(and#(reader macros.
5 Interpretation of unclear parts of the specification ¶
This chapter describes Eclector’s interpretation of passages in the Common Lisp specification that do not describe the behavior of a conforming reader completely unambiguously.
5.1 Interpretation of Sharpsign C and Sharpsign S ¶
At first glance, Sharpsign C and Sharpsign S seem to follow the same syntactic structure: the dispatch macro character followed by the sub-character followed by a list of a specific structure. However, the actual descriptions of the respective syntax is different. For Sharpsign C, the specification states:
#Creads a following object, which must be a list of length two whose elements are both reals.
For Sharpsign S, on the other hand, the specification describes the syntax as:
#s(name slot1 value1 slot2 value2 ...)denotes a structure.
Note how the description for Sharpsign C relies on a recursive read
invocation while the description for Sharpsign S gives a character-level
pattern with meta-syntactic variables. It is possible that this is an
oversight and the syntax was intended to be uniform between the two
reader macros. Whatever the case may be, in order to handle existing
code without inconveniencing clients, Eclector implements both
Sharpsign C and Sharpsign S with a recursive read invocation which
corresponds to permissive behavior.
More concretely, Eclector behaves as summarized in the following table:
| Input | Behavior |
|---|---|
#C(1 2) | Read as #C(1 2) |
#C (1 2) | Read as #C(1 2) |
#C#||#(1 2) | Read as #C(1 2) |
#C#.(list 1 (+ 2 3)) | Read as #C(1 5) |
#C[1 2] for left-parenthesis syntax on [ | Read as #C(1 2) |
#S(foo) | Read as #S(foo) |
#S (foo) | Read as #S(foo) |
#S#||#(foo) | Read as #S(foo) |
#S#.(list 'foo) | Read as #S(foo) |
#S[foo] for left-parenthesis syntax on [ | Read as #S(foo) |
Eclector provides a strict version of the Sharpsign C macro function
under the name eclector.reader:strict-sharpsign-c which behaves as
follows:
| Input | Behavior |
|---|---|
#C(1 2) | Read as #C(1 2) |
#C (1 2) | Rejected |
#C#||#(1 2) | Rejected |
#C#.(list 1 (+ 2 3)) | Rejected |
#C[1 2] for left-parenthesis syntax on [ | Read as #C(1 2) |
Eclector provides a strict version of the Sharpsign S macro function
under the name eclector.reader:strict-sharpsign-s which behaves as
follows:
| Input | Behavior |
|---|---|
#S(foo) | Read as #S(foo) |
#S (foo) | Rejected |
#S#||#(foo) | Rejected |
#S#.(list 'foo) | Rejected |
#S[foo] for left-parenthesis syntax on [ | Rejected |
5.2 Interpretation of Backquote and Sharpsign Single Quote ¶
The Common Lisp specification is very specific about the contexts in
which the quasiquotation mechanism can be used. Explicit descriptions
of the behavior of the quasiquotation mechanism are given for
expressions which are lists or vectors and it is implied that
unquote is not allowed in other expressions. From this description, it
is clear that `#S(foo :bar ,x) is not valid syntax, for example.
However, whether `#',foo is valid syntax depends on whether
#'thing is considered to be a list. Since `#',foo
is a relatively common idiom, Eclector accepts it by default.
Eclector provides a strict version of the Sharpsign Single Quote macro
function under the name
eclector.reader:strict-sharpsign-single-quote which does not accept
unquote in the function name.
5.3 Circular objects and custom reader macros ¶
The Common Lisp specification describes the behavior of the ##
reader macro as follows:
#n#, where n is a required unsigned decimal integer, provides a reference to some object labeled by#n=; that is,#n#represents a pointer to the same (eq) object labeled by#n=.
The vague phrasing “represents a pointer to the same (eq) object”
is probably chosen to cover the situation in which the object in
question is not yet defined when the reader encounters the #n#
reference as is the case with input of the form
#n=(…#n#…). The fact that the object is not yet defined
when the reference is encountered is not a problem in general except for
one situation: assume #_ is a custom reader macro in the current
readtable which calls read. In this situation, reading an
expression of the form #n=(…#_#n#…) causes the reader
macro function for #_ to be called which calls read to read the
following object which encounters the reference. This chain of calls
leads to a potential problem: the read call made by the reader macro
function has to return some object but it cannot return the object
labeled n since that object has not been read yet. The reader
macro function must therefore receive some sort of
implementation-dependent 5 object which stands in
for the object labeled n and gets replaced at some later time
after the object labeled n has been read. Since the stand-in
object is implementation-dependent, the reader macro function must not
make any assumptions regarding the type of the object or operate on it
in any way other than returning the object or using the object as a part
of a compound object.
The following example violates this principle since the reader macro
function in custom-macro-readtable calls cl:first on the
object returned by eclector.reader:read:
(defun custom-macro-readtable ()
(let ((readtable (eclector.readtable:copy-readtable
eclector.reader:*readtable*)))
(eclector.readtable:set-dispatch-macro-character
readtable #\# #\_ (lambda (stream char sub-char)
(declare (ignore char sub-char))
(second (eclector.reader:read stream t nil t))))
readtable))
(let ((eclector.reader:*readtable* (custom-macro-readtable)))
(eclector.reader:read-from-string "#1=(:a #_#1#)"))
⇒ undefined
To handle the problem described above, Eclector imposes the following
restriction on custom reader macro functions which call read:
A reader macro function which reads an object by calling
readmust account for the object being of an implementation-dependent type and must not operate on the object in any way other than returning the object or using the object as a part of a compound object.
Concept index ¶
| Jump to: | A B C E F L O P Q R S U |
|---|
| Jump to: | A B C E F L O P Q R S U |
|---|
Function and macro and variable and type index ¶
| Jump to: | (
*
C E F I L M N P R S V W |
|---|
| Jump to: | (
*
C E F I L M N P R S V W |
|---|
Changelog ¶
- Release 0.12 (not yet released)
-
- The deprecated generic functions
eclector.reader:call-with-current-packagehas been removed. Clients should useeclector.reader:call-with-state-valuewith thecl:*package*aspect. - Eclector no longer processes inherited symbols like
cl:floorin packageCOMMON-LISP-USERas if they were exported when spelled ascl-user:floor. Instead, Eclector now signals an error of typeeclector.reader:symbol-is-not-externalfor inputs like the above. - Eclector no longer incorrectly reads
#'nilasnil. - The following names of condition types and reader functions are now exported:
eclector.reader:dispatch-macro-character-errorwith readereclector.reader:dispatch-charactereclector.reader:character-must-be-a-dispatching-charactereclector.reader:sub-character-conditionwith readereclector.reader:sub-charactereclector.reader:sub-character-must-not-be-a-decimal-digiteclector.reader:reader-macro-parameter-errorwith readereclector.reader:macro-nameThe reader
eclector.reader:parameterforeclector.reader:numeric-parameter-supplied-but-ignoredeclector.reader:unquote-conditionwith readereclector.reader:splicingpeclector.reader:unquote-macroexpansion-errorwith readereclector.reader:argumentThe reader
eclector.reader:expected-characterforeclector.reader:invalid-context-for-right-parenthesisThe readers
eclector.reader:expressionandeclector.reader:original-conditionforeclector.reader:read-time-evaluation-errorThe reader
eclector.reader:nameforeclector.reader:unknown-character-nameeclector.reader:digit-conditionwith readereclector.reader:baseThe reader
eclector.reader:found-characterforeclector.reader:digit-expectedThe readers
eclector.reader:exponent-markerandeclector.reader:float-formatforeclector.reader:invalid-default-float-formateclector.reader:array-initialization-errorwith readereclector.reader:array-typeThe readers
eclector.reader:expected-countandeclector.reader:found-countforeclector.reader:too-many-elementsThe readers
eclector.reader:axis,eclector.reader:expected-lengthandeclector.reader:datumforeclector.reader:incorrect-initialization-lengtheclector.reader:complex-part-conditionwith readereclector.reader:whicheclector.reader:slot-value-conditionwith readereclector.reader:slot-nameeclector.reader:reader-conditional-conditionwith readereclector.reader:contextThe reader
eclector.reader:featuresforeclector.reader:single-feature-expectedeclector.reader:reference-errorwith readereclector.reader:label
- The deprecated generic functions
- Release 0.11 (2025-06-08)
-
- Major incompatible change
A
childrenparameter has been added to the lambda list of the generic functioneclector.parse-result:make-skipped-input-resultso that results which represent skipped material can have children. For example, before this change, aeclector.parse-result:readcall which encountered the expression#+no-such-feature foo barpotentially constructed parse results for all (recursive)readcalls, that is for the whole expression, forno-such-feature, forfooand forbar, but the parse results forno-such-featureandfoocould not be attached to a parent parse result and were thus lost. In other words the shape of the parse result tree wasskipped input result #+no-such-feature foo expression result bar
With this change, the parse results in question can be attached to the parse result which represents the whole
#+no-such-feature fooexpression so that the entire parse result tree has the following shapeskipped input result #+no-such-feature foo skipped input result no-such-feature skipped input result foo expression result bar
Since this is a major incompatible change, we offer the following workaround for clients that must support Eclector versions with and without this change:
(eval-when (:compile-toplevel :load-toplevel :execute) (let* ((generic-function #'eclector.parse-result:make-skipped-input-result) (lambda-list (c2mop:generic-function-lambda-list generic-function))) (when (= (length lambda-list) 5) (pushnew 'skipped-input-children *features*)))) (defmethod eclector.parse-result:make-skipped-input-result ((client client) (stream t) (reason t) #+PACKAGE-THIS-CODE-IS-READ-IN::skipped-input-children (children t) (source t)) ... #+PACKAGE-THIS-CODE-IS-READ-IN::skipped-input-children (use children) ...)The above code pushes a symbol that is interned in a package under the control of the respective client (as opposed to the
KEYWORDpackage) ontocl:*features*before the second form is read and uses that feature to select either the version with or the version without thechildrenparameter of the method definition. See Maintaining Portable Lisp Programs by Christophe Rhodes for a detailed discussion of this technique. - The new condition type
eclector.reader:state-value-type-errorcan be used to indicate that a value of an unsuitable type has been provided for a reader state aspect. - The reader state protocol (See Reader state protocol) now provides the
generic function
(setf eclector.reader:state-value)which allows clients to set reader state aspects in addition to establishing dynamically scoped bindings. - The macros
eclector.reader:unquoteandeclector.reader:unquote-splicingnow signal sensible errors when used outside of the lexical scope of aeclector.reader:quasiquotemacro call. Note that the name of the associated condition type is not exported for now since quasiquotation will be implemented in a separate module in the future.Such invalid uses can happen when the above macros are called directly or when the
,,,@and,.reader macros are used in a way that constructs the unquoted expression in one context and then "injects" it into some other context, for example via an object reference#N#or read-time evaluation#.(...). Full example:(progn (print `(a #1=,(+ 1 2) c)) (print #1#))
Another minor aspect of this change is that the condition types
eclector.reader:unquote-splicing-in-dotted-listandeclector.reader:unquote-splicing-at-topare no longer subtypes ofcommon-lisp:stream-error. The previous relation did not make sense since errors of those types are signaled during macro expansion. - Eclector now uses the reader state protocol (See Reader state protocol)
instead of plain special variables to query and track the legality of
quasiquotation operations and the consing dot. The additional reader state
aspects are documented but remain internal for now.
The (internal) macro
eclector.reader::with-forbidden-quasiquotationis deprecated as of this release. Clients which really need a replacement immediately can use the new (internal) macroeclector.reader::with-quasiquotation-state. - Eclector no longer returns incorrect parse results when custom reader macros
bypass some reader functionality and the input contains labeled object
definitions or references.
An example of a situation that was previously handled incorrectly is the following
(defun bypassing-left-parenthesis (stream char) (declare (ignore char)) (loop for peek = (eclector.reader:peek-char t stream t nil t) when (eq peek #\)) do (eclector.reader:read-char stream t nil t) (loop-finish) collect (let ((function (eclector.readtable:get-macro-character eclector.reader:*readtable* peek))) (cond (function (eclector.reader:read-char stream t nil t) (funcall function stream peek)) (t (eclector.reader:read stream t nil t)))))) (let ((eclector.reader:*readtable* (eclector.readtable:copy-readtable eclector.reader:*readtable*))) (eclector.readtable:set-macro-character eclector.reader:*readtable* #\( #'bypassing-left-parenthesis) (describe (eclector.parse-result:read-from-string (make-instance 'eclector.parse-result.test::simple-result-client) "(print (quote #1=(member :floor :ceiling)))"))) ;; [...] ;; Slots with :INSTANCE allocation: ;; %RAW = (PRINT '(MEMBER :FLOOR :CEILING)) ;; %SOURCE = (0 . 43) ;; [...] ;; The %RAW slot used to contain (MEMBER :FLOOR :CEILING) instead of ;; (PRINT '(MEMBER :FLOOR :CEILING)). - The reader macros for non-decimal radices now accept
+in the sign part. For example, Eclector now accepts#x+10as a spelling of16. - The reader macros for non-decimal radices now treat non-terminating macro
characters that are valid digits for the respective rational syntax as digits
instead of signaling an error. This is in line with the behavior for tokens
outside of those reader macros.
As an example, the following signaled an error before this change:
(let ((eclector.reader:*readtable* (eclector.readtable:copy-readtable eclector.reader:*readtable*))) (eclector.readtable:set-macro-character eclector.reader:*readtable* #\1 (lambda (stream char) (declare (ignore stream char)) 1) t) ; non-terminating (eclector.reader:read-from-string "#x01")) - When producing parse results and recovering from an invalid input of a form like
#1= ;; a ;; b <eof>
Eclector no longer returns an invalid parse result graph.
- When producing parse results and recovering from an invalid input of a form
like
#1=#1#, Eclector no longer returns an invalid parse result graph. - The new generic function
eclector.reader:new-value-for-fixupis called byeclector.reader:fixupto compute the replacement value for a labeled object marker, both in ordinary objects and in parse results. Clients can define methods on the new generic function to customize such replacements which is probably only useful when parse results are processed since there is not a lot of leeway in the processing of ordinary objects. - There is now a default method on
eclector.reader:fixup-graph-pwhich returns true ifeclector.reader:labeled-object-stateindicates that the labeled object in question is final and circular. - When
eclector.parse-result:parse-result-clientis used,eclector.reader:labeled-object-statenow returns inner labeled object as its fourth value. - Elector now breaks up long chains of recursive
eclector.reader:fixupcalls in order to avoid exhausting available stack space. As a consequence, methods on the generic functioneclector.reader:fixupcan no longer assume an unbroken chain of recursive calls that correspond to the nesting structure of the object graph that is being fixed up. In particular, a call for an inner object cannot rely on the fact that a particular dynamic environment established by a call for an outer object is still active.
- Major incompatible change
- Release 0.10 (2024-02-28)
-
- The deprecated generic functions
eclector.parse-result:source-positionandeclector.parse-result:make-source-rangehave been removed. Clients should useeclector.base:source-positionandeclector.base:make-source-rangerespectively instead. - The new reader
eclector.base:range-lengthcan be applied to conditions of typeeclector.base:stream-position-condition(which includes almost all conditions related to syntax errors) to determine the length of the sub-sequence of the input to which the condition in question pertains. - Minor incompatible change
The part of the labeled objects protocol that allows clients to construct parse results which represent labeled objects has been changed in an incompatible way. The change allows parse results which represent labeled objects to have child parse results but requires that clients construct parse results which represent labeled objects differently: instead of eql-specializing the
resultparameters of methods oneclector.parse-result:make-expression-resulttoeclector.parse-result:**definition**andeclector.parse-result:**reference**and receiving the labeled object in thechildrenparameters, theresultparameters now have to be specialized to the classeseclector.parse-result:definitionandeclector.parse-result:referencerespectively. The object passed as theresultargument now contains the labeled object so that thechildrenparameter can receive child parse results.This change is considered minor since the old mechanism described above was not documented. For now, the new mechanism also remains undocumented so that the design can be validated through experimentation before it is finalized.
- The new
syntax-extensionsmodule contains a collection of syntax extensions which are implemented as either mixin classes for clients or reader macro functions. - The extended package prefix extension allows prefixing an expression with a
package designator in order to read the expression with the designated package
as the current package. For example
my-package::(a b)
is read as
(my-package::a my-package::b)
with this extension.
- A new syntax extension which is implemented by the reader macro
eclector.syntax-extensions.s-expression-comment:s-expression-commentallows commenting out s-expressions in a fashion similar to SRFI 62 for scheme. One difference is that a numeric infix argument can be used to comment out a number of s-expressions different from 1:(frob r1 r2 :k3 4 #4; :k5 6 :k6 7)
- The
concrete-syntax-treemodule now produces a better tree structure for certain inputs like(0 . 0). Before this change the produced CST had the sameconcrete-syntax-tree:atom-cstobject as theconcrete-syntax-tree:firstandconcrete-syntax-tree:restof the outerconcrete-syntax-tree:cons-cstnode. After this change theconcrete-syntax-tree:firstchild is theconcrete-syntax-tree:atom-cstwhich corresponds to the first0in the input and theconcrete-syntax-tree:restchild is theconcrete-syntax-tree:atom-cstwhich corresponds to the second0in the input. In contrast to the previous example, an input like(#1=0 . #1#)continues to result in a singleconcrete-syntax-tree:atom-cstin both theconcrete-syntax-tree:firstandconcrete-syntax-tree:restslots of the outerconcrete-syntax-tree:cons-cstobject.
- The deprecated generic functions
- Release 0.9 (2023-03-19)
-
- The deprecated function
eclector.concrete-syntax-tree:cst-readhas been removed. Clients should useeclector.concrete-syntax-tree:readinstead. eclector.reader:find-characterreceives characters names with unmodified case and is also called in the#\<single character>case so that clients have more control over character lookup.- The new generic function
eclector.base:position-offsetallows interested clients to refine the source positions of errors obtained by callingeclector.base:stream-position. - Some condition and restart reports have been improved.
- A discussion of the relation between circular objects and custom reader macros has been added to the manual (See Circular objects and custom reader macros).
- Problems in the
eclector.reader:fixupmethod for hash tables have been fixed: keys were not checked for circular structure and circular structures in values were not fixed up in some cases. - Eclector provides a new protocol for handling labeled objects, that is the
objects defined and referenced by the
#=and##reader macros respectively (See Labeled objects and references). - Eclector now avoids unnecessary fixup processing in object graphs with
complicated definitions and references.
Before this change, cases like
#1=(1 #1# #2=(2 #2# ... #100=(100 #100#)))
or
#1=(1 #2=(2 ... #2#) ... #1#)
led to unnecessary and/or repeated traversals during fixup processing.
- Fixup processing is now performed in parse result objects.
Before this change, something like
(eclector.concrete-syntax-tree:read-from-string "#1=(#1#)")
produced a CST object, say
cst, which failed to satisfy(eq (cst:first cst) cst) (eq (cst:raw (first cst)) (cst:raw cst))
The properties now hold.
- Clients can use the new mixin classes
eclector.concrete-syntax-tree:definition-csts-mixinandeclector.concrete-syntax-tree:reference-csts-mixinto represent labeled object definitions and references as instances ofeclector.concrete-syntax-tree:definition-cstandeclector.concrete-syntax-tree:reference-cstrespectively. - The stream position in conditions signaled by
eclector.reader::sharpsign-colonis now always present. - When Eclector is used to produce parse results, it no longer confuses
end-of-input with having read
cl:nilwhencl:nilis used as theeof-value(cl:nilmakes sense as aneof-valuein that case sincecl:nilis generally not a possible parse result). - A detailed description of the constraints on return values of the generic functions in the Reader behavior protocol has been added to the manual (See Reader behavior protocol).
- The
eclector-concrete-syntax-treesystem now works with and requires version 0.2 of theconcrete-syntax-treesystem. - Eclector provides a new protocol for querying and binding behavior-changing
aspects of the current state of the reader such as the current package, the
current readtable and the current read base (See Reader state protocol).
Clients can use this protocol to control the reader state in other ways than binding the Common Lisp variables, for example by storing the values of reader state aspects in context objects.
Furthermore, implementations which use Eclector as the Common Lisp reader can use this protocol to tie the
cl:*readtable*aspect to thecl:*readtable*variable instead of theeclector.reader:*readtable*variable.The new protocol subsumes the purpose of the generic function
eclector.reader:call-with-current-packagewhich is deprecated as of this Eclector version. - Eclector now provides and uses by default a relaxed version of the
eclector.reader::sharpsign-sreader macro function which requires the input following#Sto be read as a list but not necessarily be literally written as(TYPE INITARG₁ VALUE₁ …).A detailed discussion of the topic has been added to the manual (See Interpretation of Sharpsign C and Sharpsign S).
- The deprecated function
- Release 0.8 (2021-08-24)
-
- The default
eclector.reader:read-tokenmethod and the functionseclector.reader::sharpsign-colonandeclector.reader::sharpsign-backslashare now more efficient as well as less redundant in terms of repeated code. - The feature
:eclector-define-cl-variablesnow controls whether the filecode/reader/variables.lispis loaded and thus whether the variableseclector.reader:*package*,eclector.reader:*read-eval*, etc. are defined.
- The default
- Release 0.7 (2021-05-16)
-
- The incorrectly committed generic function
eclector.reader:check-symbol-tokenhas been fixed. - Empty escape ranges like
||are no longer interpreted as potential numbers. - The default
eclector.reader:interpret-symbolmethod now signals specific conditions and offers restarts for recovering from situations related to non-existent packages and symbols as well as non-exported symbols.The default error recovery strategy for invalid symbols now constructs an uninterned symbol of the given name instead of using
cl:nil. - The "consing dot" is no longer accepted in sub-expressions of
eclector.reader::left-parenthesis.At the same time, it is now possible to recover from encountering the "consing dot" in invalid positions.
- The default
eclector.reader:interpret-tokenmethod has been optimized substantially. - The
eclector.reader:*client*variable and the source location protocol (that is the generic functionseclector.parse-result:source-positionandeclector.parse-result:make-source-range) have been moved to a newbasemodule and packageeclector.basewhich thereadermodule and theeclector.readerpackage can use. This structure allows code in thereadermodule to work with source locations.The name
eclector.base:*client*remains exported aseclector.reader:*client*.The old names
eclector.parse-result:source-positionandeclector.parse-result:make-source-rangestill exist but are now deprecated and will be removed in a future release. - Conditions signaled by code in the
readermodule now include source positions which are obtained by callingeclector.base:source-position.
- The incorrectly committed generic function
- Release 0.6 (2020-11-29)
-
- Bogus
nilparse results are no longer generated byeclector.parse-result:make-skipped-input-resultcalls whencl:*read-suppress*is true. - The new generic functions
eclector.reader:read-maybe-nothingandeclector.reader:call-as-top-level-readgive clients additional entry points to the reader as well as customization possibilities. With these functions, the chain of functions calls for aeclector.reader:readcall looks like this:eclector.reader:read eclector.reader:call-as-top-level-read eclector.reader:read-common eclector.reader:read-maybe-nothing ... eclector.reader:read-char eclector.reader:peek-charDiagrams which illustrate the relations between the new and existing functions have been added to the manual (Figure 2.1, Figure 2.2, Figure 2.5).
- The function
eclector.reader::read-rationalnow better respects the value ofcl:*read-suppress*. - Fix return value of
eclector.readtable:set-syntax-from-char, fix(setf eclector.readtable:syntax-from-char)to also copy the macro character information. - The semicolon reader macro now consumes the terminating newline character.
- Eclector now provides the generic function
eclector.reader:wrap-in-function. - Reset
eclector.reader::*list-reader*around recursive read ineclector.reader::sharpsign-dot. - Implement and default to relaxed syntax for
eclector.reader::sharpsign-c. The strict version is still available aseclector.reader:strict-sharpsign-cand can be installed into a custom readtable.A detailed discussion of the topic has been added to the manual (See Interpretation of Sharpsign C and Sharpsign S).
- Eclector can now recover from reading invalid inputs like
..and.... - Implement and default to relaxed syntax for
eclector.reader::sharpsign-single-quote. The strict version is still available aseclector.reader:strict-sharpsign-single-quoteand can be installed into a custom readtable.A detailed discussion of the topic has been added to the manual (See Interpretation of Backquote and Sharpsign Single Quote).
- Eclector now provides the generic function
eclector.reader:check-symbol-token. - Input of the form
PACKAGE::||is now correctly read as a symbol. - Eclector can now recover from reading the invalid input
:.
- Bogus
- Release 0.5 (2020-06-09)
-
- The generic function
eclector.reader:call-with-current-packagehas been added. - The previously missing functions
eclector.parse-result:read-preserving-whitespaceandeclector.parse-result:read-from-stringhave been added. - The previously missing functions
eclector.concrete-syntax-tree:read-preserving-whitespaceandeclector.concrete-syntax-tree:read-from-stringhave been added. - The function
eclector.concrete-syntax-tree:cst-readhas been renamed toeclector.concrete-syntax-tree:read.eclector.concrete-syntax-tree:cst-readstill exists but is deprecated and will be removed in a future version. - Quasiquote and unquote are now opt-out instead of opt-in. This allows
quasiquotation in custom reader macros by default. The new macro
eclector.reader::with-forbidden-quasiquotationis used by Eclector (and can be used in custom reader macros) to control this behavior. - A method on
eclector.readtable:readtablepfor the simple readtable implementation has been added. - The condition type
eclector.base:end-of-fileis now a subtype ofcl:stream-errorbut not ofcl:reader-error. - An error is now always signaled independently of the the value of the
eof-errorparameter when the end of input is encountered a after single escape or within a multiple escape. The new error conditionseclector.reader:unterminated-single-escapeandeclector.reader:unterminated-multiple-escapeare signaled in such situations. - The set invalid sub-characters for
#now conforms to the specification. - The value of
cl:*read-base*is now used correctly when distinguishing numbers and symbols. - When a number with a denominator of zero is read the new condition
eclector.reader:zero-denominatoris signaled. - The function
eclector.reader:read-delimited-listhas been added. - The reader macro function
eclector.reader::sharpsign-snow accepts string designators as slot names. - The reader macro functions
eclector.reader::sharpsign-equalsandeclector.reader::sharpsign-sharpsignrespect the value ofcl:*read-suppress*. - The default methods on the generic function
eclector.reader:fixupnow works correctly forcl:standard-objectinstances with unbound slots. - The reader macro function
eclector.reader::left-parenthesisnow always reads until#\), not some "opposite" character. eclector.reader:*skip-reason*is now set correctly when a line comment at the end of input is read.- In almost all situations in which Eclector signals a syntax error, a restart
named
eclector.reader:recoveris now established which, when invoked performs some action which allows the remainder of the expression to be read. The convenience functioneclector.reader:recovercan be used to invoke the restart.
- The generic function
- Release 0.4 (2019-05-11)
-
- The reader macro function
eclector.reader::sharpsign-plus-minusnow setseclector.reader:*skip-reason*so that parse results can be created with an accurate "reason" value. - Constituent traits are now represented and used properly.
- The lambda lists of the functions
eclector.reader:read-charandeclector.reader:peek-charhave been fixed. - The function
eclector.reader::read-rationalnow respectscl:*read-suppress*and handles inputs of the form1 2correctly. - The reader macro function
eclector.reader::sharpsign-rnow handlescl:*read-suppress*better. - The default method on the generic function
eclector.reader:interpret-tokennow distinguishes positive and negative float zeros and uses radix 10 instead of the value ofcl:*read-base*for float digits. - The input
.||is now interpreted as a symbol instead of the "consing dot". - Long lists are now read into concrete syntax tree results without relying on unbounded recursion.
- Syntax errors in the initial contents part of
#Aexpressions now signal appropriate errors. - Source ranges of parse results no longer include whitespace which followed the corresponding expression in the input.
- The lambda list of the function
eclector.parse-result:readis now accurate.
- The reader macro function
- Release 0.3 (2018-11-28)
-
- The function
eclector.reader:peek-charhas been added. The new function is likecl:peek-charbut signals Eclector conditions and uses the Eclector readtable. - The function
eclector.reader:read-from-stringhas been added. The new function is likecl:read-from-stringbut uses Eclector’s reader implementation. - The reader macro function
eclector.reader::sharpsign-sand the generic functioneclector.reader:make-structure-instancehave been added. Eclector does not define any methods on the latter generic function since there is no portable way of creating a structure instance when only the symbol naming the structure is known. - The generic function
eclector.reader:interpret-symbolis now called when the reader creates uninterned symbols. - The generic function
eclector.reader:fixupnow accepts a client object as the the argument. - In the generic functions
eclector.reader:wrap-in-quasiquote,eclector.reader:wrap-in-unquoteandeclector.reader:wrap-in-unquote-splicing, the client parameter is now the first parameter. - The generic function
eclector.reader:wrap-in-quotehas been added.
- The function
- Release 0.2 (2018-08-13)
-
- The
concrete-syntax-treemodule has been generalized into aparse-resultmodule which provides a protocol for constructing arbitrary custom parse results. Theconcrete-syntax-treemodule is now based on this new module but can be used as before by clients. - The default value of the
eof-error-pparameter of theeclector.reader:read-charfunction is now true.
- The
- Release 0.1 (2018-08-10)
-
- Eclector was created by extracting the reader module from the SICL repository.
- The initial release includes many improvements over the original SICL reader, particularly in the areas of customizability, error reporting and constructing parse results.